
This tool is currently only available in nightly builds.
Meta
O objetivo dessa ferramenta é fornecer uma visão geral da performance de um sistema de TPU e permitir que um analista de performance identifique partes do sistema que possam estar com problemas de desempenho.
Visualizar a utilização no nível do chip
Para usar a ferramenta, no "Drawer" à esquerda, procure "Visualizador de utilização". A ferramenta mostra quatro gráficos de barras com a utilização de unidades de execução (os dois de cima) e caminhos de DMA (os dois de baixo) para os dois nós do tensor em um chip de TPU.
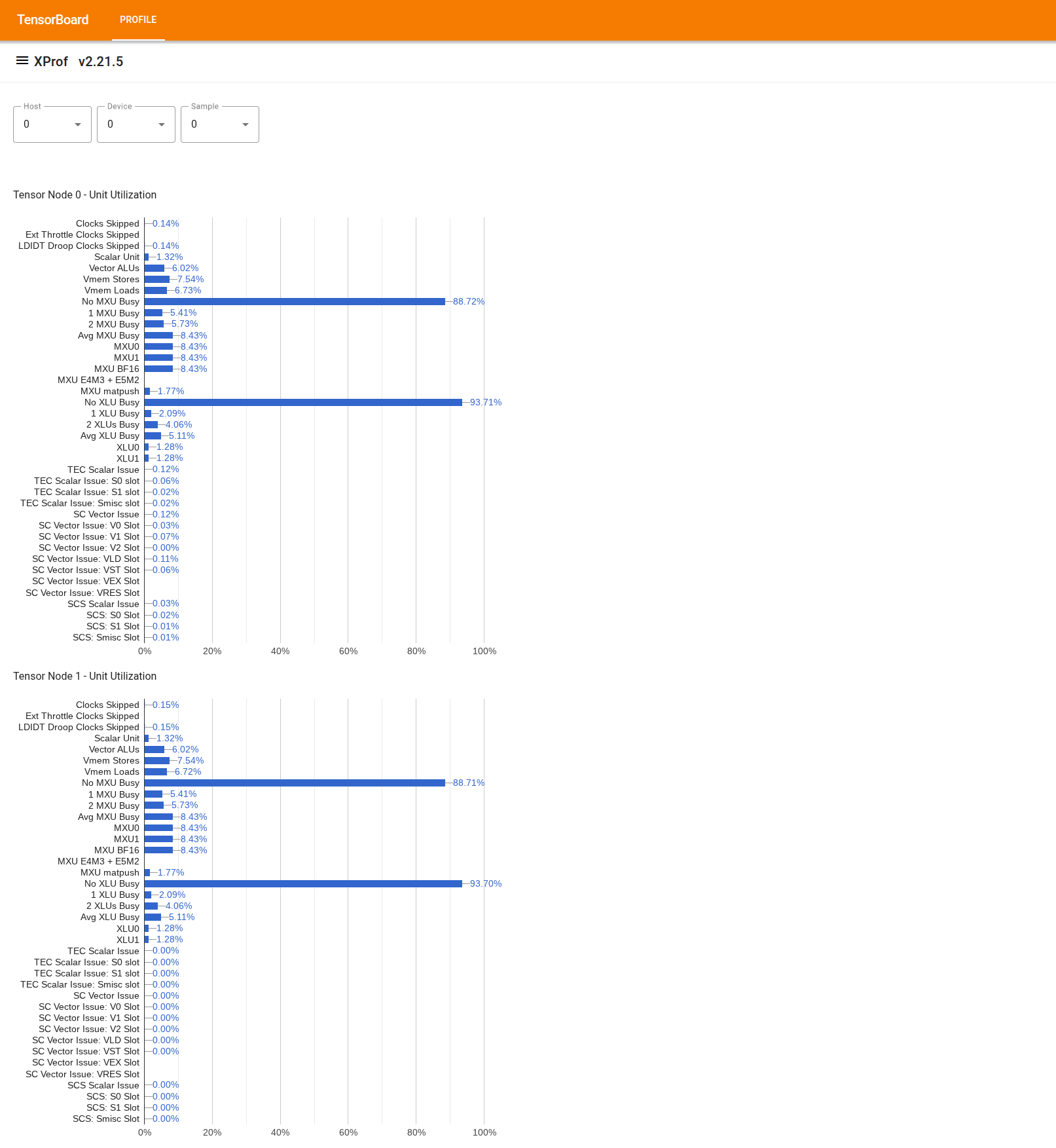
Ao passar o cursor sobre uma barra, uma dica aparece com detalhes sobre a utilização: valores "alcançados" e "máximos" (teóricos). A porcentagem de utilização mostrada na barra é obtida dividindo o valor "alcançado" pelo valor "máximo". Os valores alcançados e máximos são expressos em unidades de instruções para a utilização da unidade de execução e bytes para a utilização da largura de banda.
A utilização de uma unidade de execução é a fração de ciclos em que a unidade ficou ocupada durante o período de criação de perfil.
A utilização das seguintes unidades de execução do Tensor Core é mostrada:
- Unidade escalar: calculada como a soma de
count_s0_instructionecount_s1_instruction, ou seja, o número de instruções escalares dividido pelo dobro do número de ciclos, porque a taxa de transferência da unidade escalar é de duas instruções por ciclo. - ALUs vetoriais: calculado como a soma de
count_v0_instructionecount_v1_instruction, ou seja, o número de instruções vetoriais dividido pelo dobro do número de ciclos, porque a capacidade de processamento das ALUs vetoriais é de duas instruções por ciclo. - Armazenamentos de vetores: calculado como
count_vector_store, ou seja, o número de armazenamentos de vetores dividido pelo número de ciclos, porque a taxa de transferência do armazenamento de vetores é de uma instrução por ciclo. - Cargas de vetor: calculado como
count_vector_load, ou seja, o número de cargas de vetor dividido pelo número de ciclos, porque a taxa de transferência de carga de vetor é de uma instrução por ciclo. - Unidade de matriz (MXU): calculada como
count_matmuldividido por 1/8 do número de ciclos, porque a taxa de transferência da MXU é de uma instrução por oito ciclos. - Unidade de transposição (XU): calculada como
count_transposedividido por 1/8 do número de ciclos, porque a capacidade de processamento da XU é de uma instrução por oito ciclos. - Unidade de redução e permutação (RPU): calculada como
count_rpu_instructiondividido por 1/8 do número de ciclos, porque a capacidade da RPU é de uma instrução por oito ciclos.
A figura a seguir é um diagrama de blocos do núcleo de tensor que mostra as unidades de execução:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisiblePara mais detalhes sobre cada uma dessas unidades de execução, consulte Arquitetura de TPU.
- Unidade escalar: calculada como a soma de
A utilização de caminhos de DMA é a fração da largura de banda (bytes/ciclo) usada durante o período de criação de perfil. Ele é derivado dos contadores NF_CTRL.
A figura a seguir mostra sete nós que representam origens / destinos de DMAs e os 14 caminhos de DMA em um nó de tensor. Os caminhos "BMem para VMem" e "Bmem para ICI" na figura são, na verdade, um caminho compartilhado acumulado por um único contador, mostrado como "BMem para ICI/VMem" na ferramenta. Um DMA enviado ao ICI é um DMA para uma HBM ou VMEM remota, enquanto um DMA de/para HIB é um DMA de/para a memória do host.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI