
This tool is currently only available in nightly builds.
Цель
Цель этого инструмента — предоставить общий обзор производительности системы TPU и позволить аналитику производительности выявить те участки системы, которые могут испытывать проблемы с производительностью.
Визуализация использования на уровне микросхемы
Чтобы использовать инструмент, в левой боковой панели найдите инструмент «Просмотр использования». Инструмент отображает 4 столбчатых диаграммы, показывающие использование исполнительных блоков (2 верхние диаграммы) и путей DMA (2 нижние диаграммы) для 2 узлов Tensor в чипе TPU.
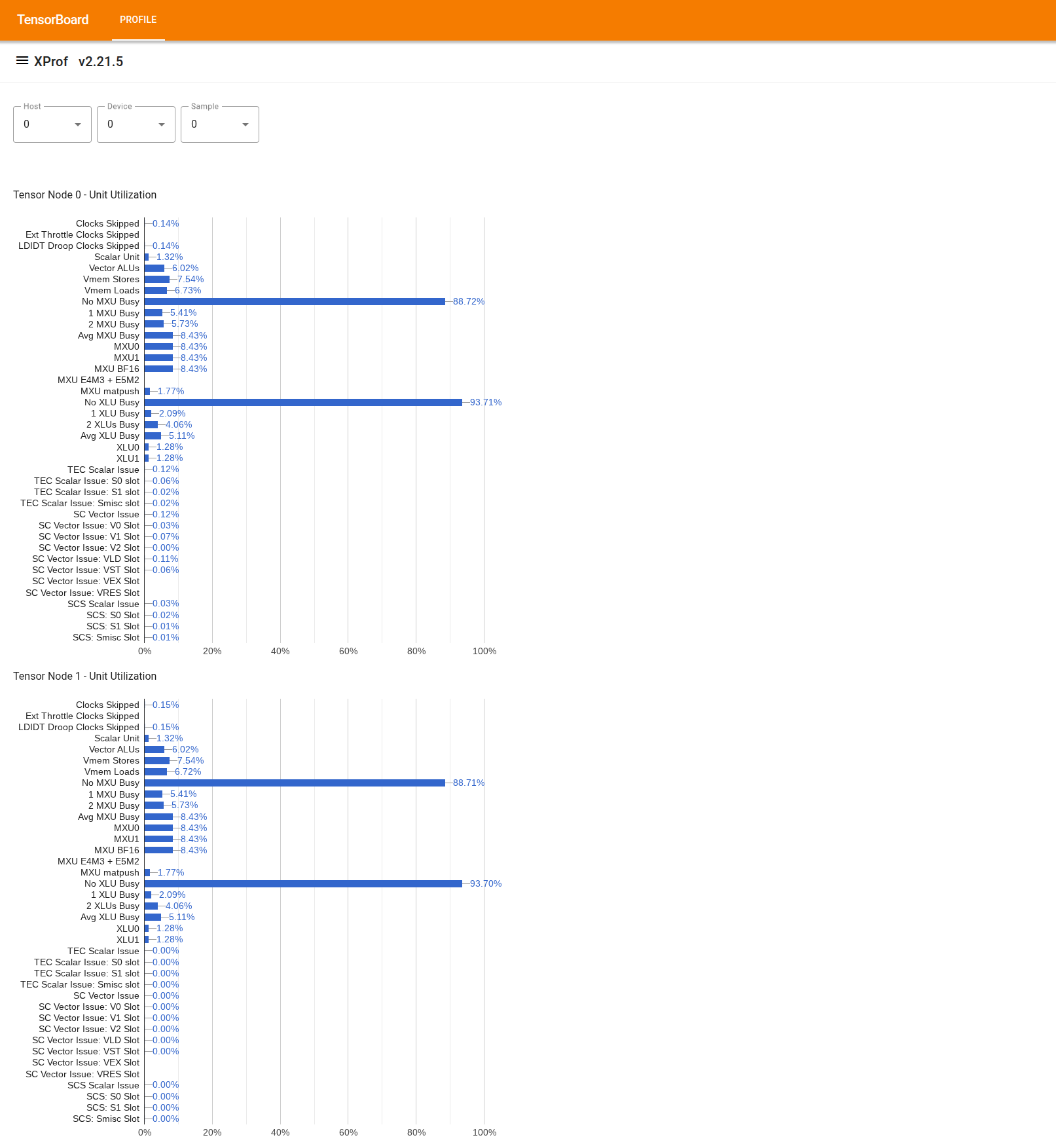
При наведении курсора на полосу отображается всплывающая подсказка с подробной информацией об использовании: «достигнутое» и (теоретическое) «пиковое» значения. Процент использования, отображаемый на полосе, получается путем деления «достигнутого» значения на «пиковое». Достигнутое и пиковое значения выражаются в единицах инструкций для использования исполнительного блока и в байтах для использования полосы пропускания.
Коэффициент использования исполнительного блока — это доля циклов, в течение которых блок был занят в период профилирования.
Показано использование следующих исполнительных блоков Tensor Core:
- Скалярный блок : вычисляется как сумма
count_s0_instructionиcount_s1_instruction, то есть количество скалярных инструкций, деленное на удвоенное количество циклов, поскольку пропускная способность скалярного блока составляет 2 инструкции за цикл. - Векторные АЛУ : вычисляются как сумма
count_v0_instructionиcount_v1_instruction, то есть количества векторных инструкций, деленная на удвоенное количество циклов, поскольку пропускная способность векторных АЛУ составляет 2 инструкции за цикл. - Количество операций записи векторов : вычисляется как
count_vector_store, т.е. количество операций записи векторов, деленное на количество циклов, поскольку пропускная способность операции записи векторов составляет 1 инструкцию за цикл. - Векторные загрузки : вычисляется как
count_vector_load, т.е. количество векторных загрузок, деленное на количество циклов, поскольку пропускная способность векторной загрузки составляет 1 инструкцию за цикл. - Матричный блок (MXU) : вычисляется как
count_matmulделенное на 1/8 числа циклов, поскольку пропускная способность MXU составляет 1 инструкцию за 8 циклов. - Транспонированный блок (XU) : вычисляется как
count_transposeделенное на 1/8 от количества циклов, поскольку пропускная способность XU составляет 1 инструкцию за 8 циклов. - Блок сокращения и перестановки (RPU) : вычисляется как
count_rpu_instructionделенное на 1/8 от количества циклов, поскольку пропускная способность RPU составляет 1 инструкцию за 8 циклов.
На следующем рисунке представлена блок-схема тензорного ядра, демонстрирующая исполнительные блоки:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleДля получения более подробной информации о каждом из этих исполнительных блоков, пожалуйста, обратитесь к разделу «Архитектура TPU» .
- Скалярный блок : вычисляется как сумма
Показатель использования каналов DMA — это доля полосы пропускания (байты/цикл), использованная в течение периода профилирования. Он рассчитывается на основе счетчиков NF_CTRL .
На следующем рисунке показаны 7 узлов, представляющих источники/получатели DMA, и 14 путей DMA в узле Tensor. Пути «BMem to VMem» и «Bmem to ICI» на рисунке фактически представляют собой общий путь, накапливаемый одним счетчиком, который в инструменте отображается как «BMem to ICI/VMem». DMA, отправленный в ICI, — это DMA к удаленному HBM или VMEM, тогда как DMA из/в HIB — это DMA из/в память хоста.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI