
This tool is currently only available in nightly builds.
เป้าหมาย
เป้าหมายของเครื่องมือนี้คือการให้ภาพรวมของประสิทธิภาพของระบบ TPU และช่วยให้นักวิเคราะห์ประสิทธิภาพระบุส่วนต่างๆ ของระบบที่อาจมีปัญหาด้านประสิทธิภาพ
การแสดงภาพการใช้งานระดับชิป
หากต้องการใช้เครื่องมือนี้ ให้มองหาเครื่องมือ "โปรแกรมดูการใช้งาน" จาก "ลิ้นชัก" ทางด้านซ้าย เครื่องมือจะแสดงแผนภูมิแท่ง 4 รายการที่แสดงการใช้หน่วยการดำเนินการ (2 แผนภูมิด้านบน) และเส้นทาง DMA (2 แผนภูมิด้านล่าง) สำหรับโหนด Tensor 2 รายการในชิป TPU
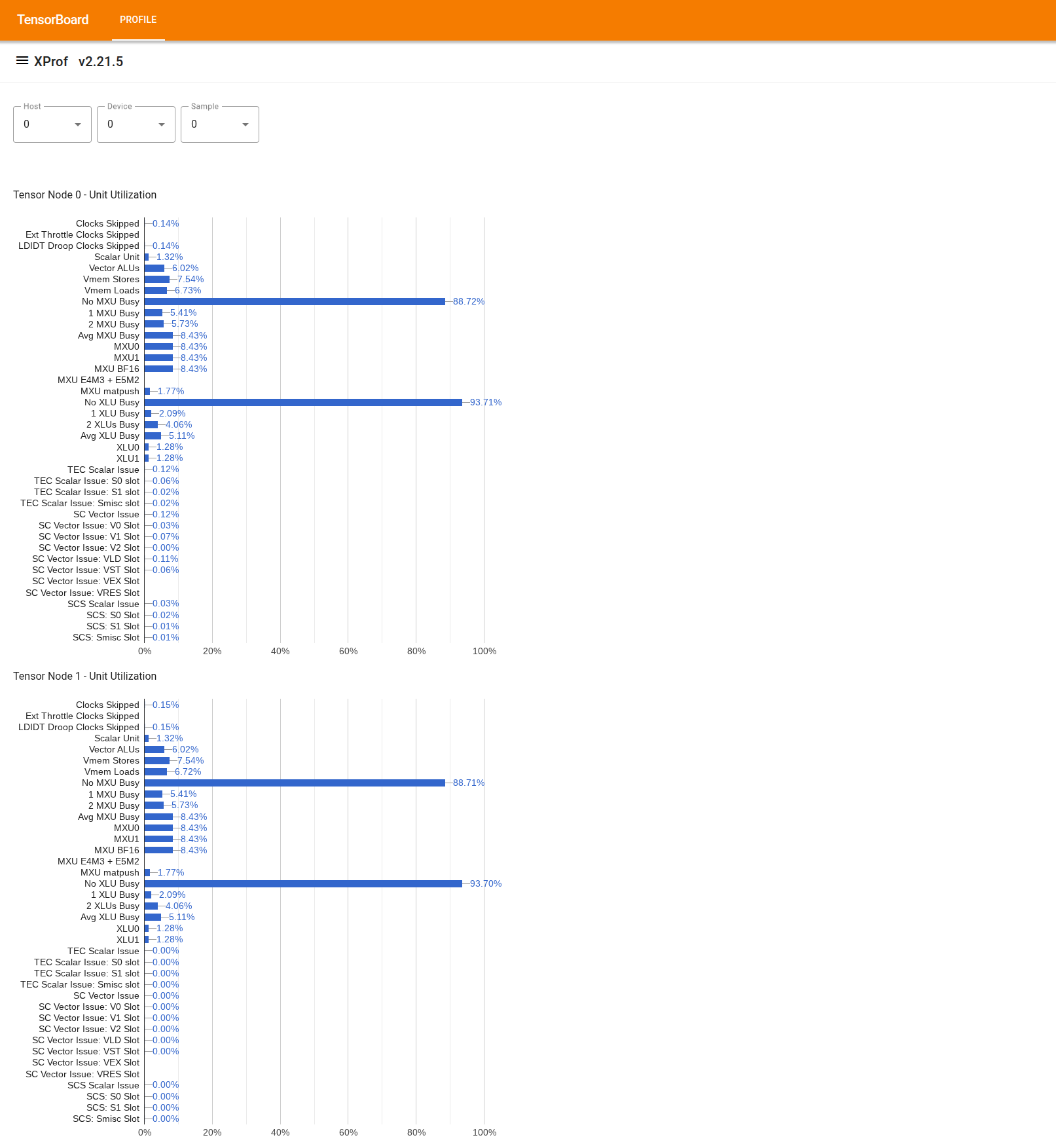
การวางเมาส์เหนือแถบจะแสดงเคล็ดลับเครื่องมือที่มีรายละเอียดเกี่ยวกับการใช้งาน ได้แก่ จำนวน "ที่ทำได้" และ "สูงสุด" (ตามทฤษฎี) เปอร์เซ็นต์การใช้งาน ที่แสดงในแถบได้มาจากการหารจำนวน "ที่ทำได้" ด้วยจำนวน "สูงสุด" ระบบจะแสดงจำนวนที่ทำได้และจำนวนสูงสุดในหน่วยของคำสั่งสำหรับการใช้หน่วยการดำเนินการ และไบต์สำหรับการใช้แบนด์วิดท์
การใช้งานหน่วยการดำเนินการคือเศษส่วนของรอบที่หน่วย ไม่ว่างภายในระยะเวลาการสร้างโปรไฟล์
การใช้งานหน่วยการประมวลผล Tensor Core ต่อไปนี้จะแสดงขึ้น
- หน่วยสเกลาร์: คำนวณเป็นผลรวมของ
count_s0_instructionและcount_s1_instructionกล่าวคือ จำนวนคำสั่งสเกลาร์ หารด้วยจำนวนรอบ 2 เท่า เนื่องจากปริมาณงานของหน่วยสเกลาร์คือ 2 คำสั่งต่อรอบ - ALU แบบเวกเตอร์: คำนวณเป็นผลรวมของ
count_v0_instructionและcount_v1_instructionกล่าวคือ จำนวนคำสั่งเวกเตอร์ หารด้วย จำนวนรอบเป็น 2 เท่า เนื่องจากปริมาณงานของ ALU แบบเวกเตอร์คือ 2 คำสั่งต่อรอบ - Vector Stores: คำนวณเป็น
count_vector_storeกล่าวคือ จำนวน Vector Stores หารด้วยจำนวนรอบ เนื่องจาก ปริมาณงานของ Vector Store คือ 1 คำสั่งต่อรอบ - การโหลดเวกเตอร์: คำนวณเป็น
count_vector_loadกล่าวคือ จำนวน การโหลดเวกเตอร์ หารด้วยจำนวนรอบ เนื่องจากปริมาณงาน การโหลดเวกเตอร์คือ 1 คำสั่งต่อรอบ - หน่วยเมทริกซ์ (MXU): คำนวณเป็น
count_matmulหารด้วย 1/8 ของ จำนวนรอบ เนื่องจากปริมาณงานของ MXU คือ 1 คำสั่งต่อ 8 รอบ - หน่วยสลับ (XU): คำนวณเป็น
count_transposeหารด้วย 1/8 ของ จำนวนรอบ เนื่องจากปริมาณงานของ XU คือ 1 คำสั่งต่อ 8 รอบ - หน่วยลดและสับเปลี่ยน (RPU): คำนวณเป็น
count_rpu_instructionหารด้วย 1/8 ของจำนวนรอบ เนื่องจาก ปริมาณงานของ RPU คือ 1 คำสั่งต่อ 8 รอบ
รูปที่ต่อไปนี้เป็นบล็อกไดอะแกรมของ Tensor Core ที่แสดง หน่วยการดำเนินการ
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleดูรายละเอียดเพิ่มเติมเกี่ยวกับหน่วยการประมวลผลแต่ละหน่วยได้ที่สถาปัตยกรรม TPU
- หน่วยสเกลาร์: คำนวณเป็นผลรวมของ
การใช้เส้นทาง DMA คือเศษส่วนของแบนด์วิดท์ (ไบต์/รอบ) ที่ใช้ในช่วงการสร้างโปรไฟล์ ซึ่งได้มาจาก ตัวนับ NF_CTRL
รูปต่อไปนี้แสดงโหนด 7 โหนดที่แสดงถึงแหล่งที่มา / ปลายทางของ DMA และเส้นทาง DMA 14 เส้นทางในโหนดเทนเซอร์ เส้นทาง "BMem to VMem" และ "Bmem to ICI" ในรูปภาพเป็นเส้นทางที่แชร์ซึ่งสะสม โดยตัวนับเดียว ซึ่งแสดงเป็น "BMem to ICI/VMem" ในเครื่องมือ DMA ที่ส่งไปยัง ICI คือ DMA ไปยัง HBM หรือ VMEM ระยะไกล ส่วน DMA จาก/ไปยัง HIB คือ DMA จาก/ไปยังหน่วยความจำของโฮสต์
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI