
This tool is currently only available in nightly builds.
Mục tiêu
Mục tiêu của công cụ này là cung cấp thông tin tổng quan về hiệu suất của một hệ thống TPU và cho phép nhà phân tích hiệu suất phát hiện các phần của hệ thống có thể gặp vấn đề về hiệu suất.
Trực quan hoá mức sử dụng ở cấp chip
Để sử dụng công cụ này, trong "Drawer" (Ngăn) ở bên trái, hãy tìm công cụ "Utilization Viewer" (Trình xem mức sử dụng). Công cụ này hiển thị 4 biểu đồ thanh cho biết mức sử dụng các đơn vị thực thi (2 biểu đồ trên cùng) và đường dẫn DMA (2 biểu đồ dưới cùng) cho 2 Nút Tensor trong một chip TPU.
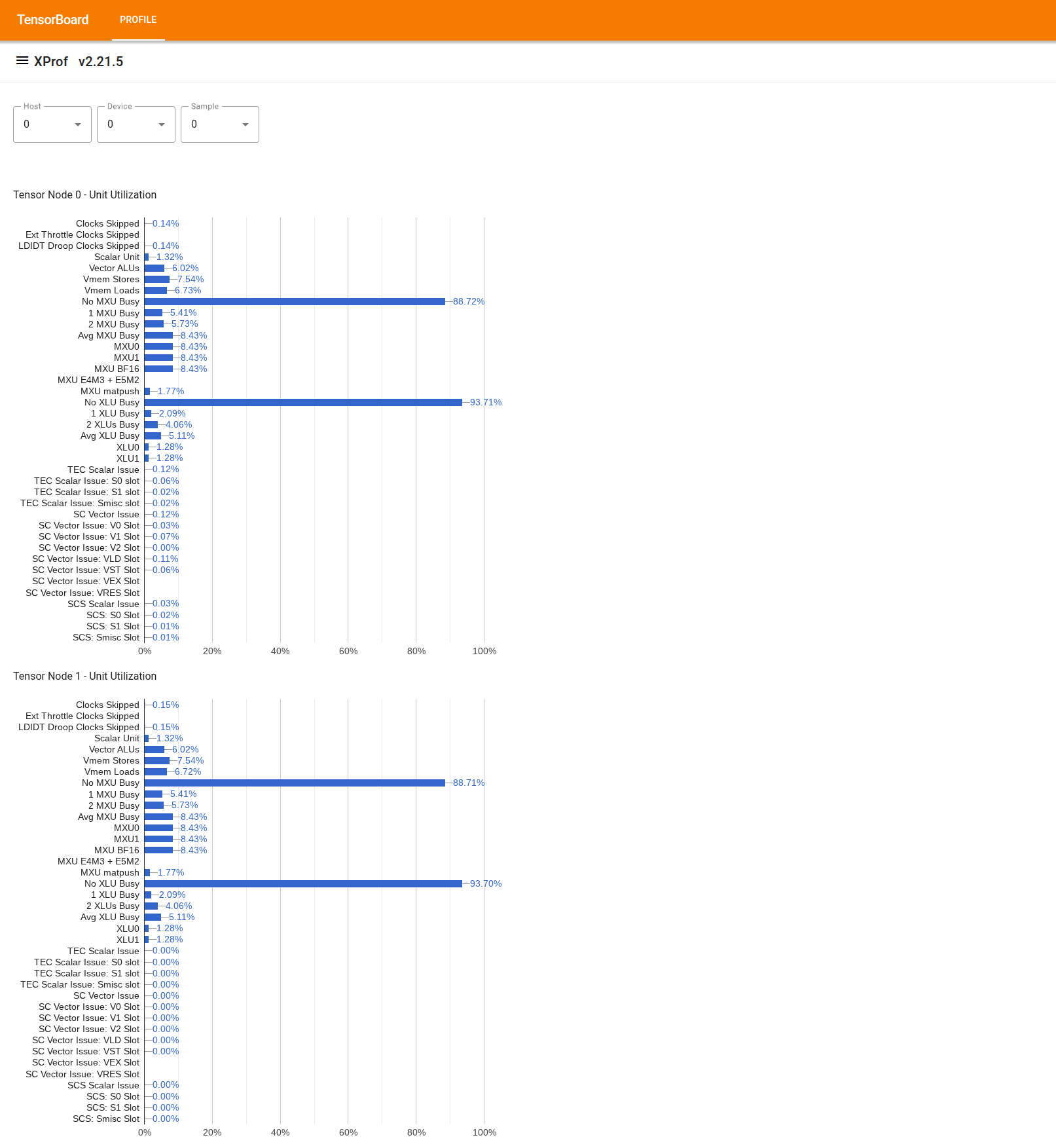
Khi di chuột lên một thanh, bạn sẽ thấy chú giải công cụ có thông tin chi tiết về mức sử dụng: số lượng "đạt được" và số lượng "đỉnh" (theo lý thuyết). Tỷ lệ phần trăm sử dụng xuất hiện trong thanh được tính bằng cách chia số tiền "đạt được" cho số tiền "cao nhất". Số lượng đạt được và số lượng cao nhất được biểu thị bằng đơn vị lệnh cho mức sử dụng đơn vị thực thi và byte cho mức sử dụng băng thông.
Mức sử dụng của một đơn vị thực thi là phần số chu kỳ mà đơn vị đó bận trong khoảng thời gian lập hồ sơ.
Mức sử dụng của các đơn vị thực thi lõi tensor sau đây:
- Đơn vị vô hướng: Được tính bằng tổng của
count_s0_instructionvàcount_s1_instruction, tức là số lượng chỉ dẫn vô hướng, chia cho số lượng chu kỳ gấp đôi, vì thông lượng của đơn vị vô hướng là 2 chỉ dẫn trên mỗi chu kỳ. - Vector ALU: Được tính bằng tổng của
count_v0_instructionvàcount_v1_instruction, tức là số lượng chỉ dẫn vectơ, chia cho số chu kỳ gấp đôi, vì thông lượng ALU vectơ là 2 chỉ dẫn trên mỗi chu kỳ. - Vector Stores (Lưu trữ vectơ): Được tính là
count_vector_store, tức là số lượng kho lưu trữ vectơ chia cho số lượng chu kỳ, vì thông lượng kho lưu trữ vectơ là 1 chỉ thị cho mỗi chu kỳ. - Tải vectơ: Được tính là
count_vector_load, tức là số lượt tải vectơ chia cho số chu kỳ, vì lưu lượng tải vectơ là 1 lệnh trên mỗi chu kỳ. - Đơn vị ma trận (MXU): Được tính bằng
count_matmulchia cho 1/8 số chu kỳ, vì thông lượng MXU là 1 chỉ thị trên 8 chu kỳ. - Đơn vị chuyển vị (XU): Được tính là
count_transposechia cho 1/8 số chu kỳ, vì thông lượng XU là 1 chỉ thị trên 8 chu kỳ. - Đơn vị giảm và hoán vị (RPU): Được tính bằng
count_rpu_instructionchia cho 1/8 số chu kỳ, vì thông lượng RPU là 1 lệnh trên 8 chu kỳ.
Hình sau đây là sơ đồ khối của lõi tensor cho thấy các đơn vị thực thi:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleĐể biết thêm thông tin chi tiết về từng đơn vị thực thi này, vui lòng tham khảo cấu trúc TPU.
- Đơn vị vô hướng: Được tính bằng tổng của
Mức sử dụng đường dẫn DMA là phần băng thông (byte/chu kỳ) được sử dụng trong khoảng thời gian lập hồ sơ. Chỉ số này được lấy từ các bộ đếm NF_CTRL.
Hình sau đây cho thấy 7 nút đại diện cho các nguồn / đích đến của DMA và 14 đường dẫn DMA trong một Nút Tensor. Các đường dẫn "BMem to VMem" và "Bmem to ICI" trong hình thực ra là một đường dẫn dùng chung được tích luỹ bằng một bộ đếm duy nhất, xuất hiện dưới dạng "BMem to ICI/VMem" trong công cụ. DMA được gửi đến ICI là DMA đến HBM hoặc VMEM từ xa, trong khi DMA từ/đến HIB là DMA từ/đến bộ nhớ máy chủ.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI