
This tool is currently only available in nightly builds.
目标
此工具旨在提供 TPU 系统的性能概览,并让性能分析师能够发现可能存在性能问题的系统部分。
直观呈现芯片级利用率
如需使用该工具,请在左侧的“抽屉”中找到“利用率查看器”工具。该工具会显示 4 个条形图,分别显示 TPU 芯片中 2 个张量节点的执行单元(前 2 个图表)和 DMA 路径(后 2 个图表)的利用率。
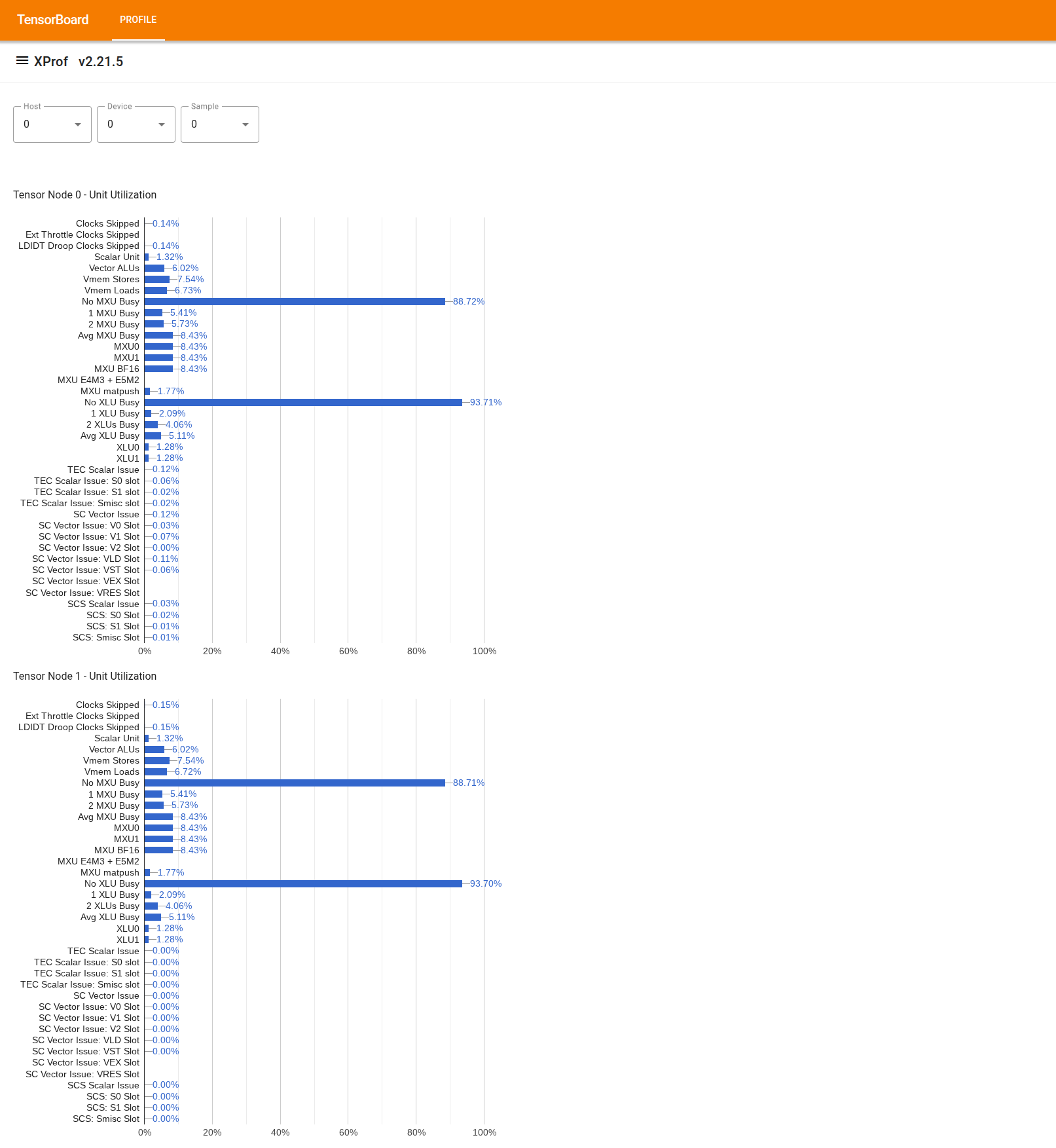
将鼠标悬停在某个条形上时,系统会显示一个提示,其中包含有关利用率的详细信息:“实际”量和(理论)“峰值”量。条形图中显示的利用率百分比是通过将“已实现”量除以“峰值”量得到的。实现量和峰值量以指令为单位表示执行单元利用率,以字节为单位表示带宽利用率。
执行单元的利用率是指在分析期间,该单元处于繁忙状态的周期所占的比例。
系统会显示以下张量核心执行单元的利用率:
- 标量单元:计算方式为
count_s0_instruction和count_s1_instruction之和,即标量指令数除以周期数的两倍,因为标量单元的吞吐量为每个周期 2 条指令。 - 向量 ALU:计算方式为
count_v0_instruction和count_v1_instruction的总和(即向量指令数)除以周期数的两倍,因为向量 ALU 的吞吐量为每个周期 2 条指令。 - 向量存储区:计算方式为
count_vector_store,即向量存储区数量除以周期数,因为向量存储区吞吐量为每个周期 1 条指令。 - 向量加载:计算方式为
count_vector_load,即向量加载次数除以周期数,因为向量加载吞吐量为每个周期 1 条指令。 - 矩阵单元 (MXU):计算方式为
count_matmul除以周期数的 1/8,因为 MXU 吞吐量为每 8 个周期 1 条指令。 - 转置单元 (XU):计算方式为
count_transpose除以周期数的 1/8,因为 XU 吞吐量为每 8 个周期 1 条指令。 - 归约和置换单元 (RPU):计算方式为
count_rpu_instruction除以周期数的 1/8,因为 RPU 的吞吐量为每 8 个周期 1 条指令。
下图是张量核心的框图,显示了执行单元:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisible如需详细了解每个执行单元,请参阅 TPU 架构。
- 标量单元:计算方式为
DMA 路径的利用率是指在分析期间使用的带宽比例(字节/周期)。它派生自 NF_CTRL 计数器。
下图显示了 7 个表示 DMA 源 / 目的地的节点,以及 Tensor 节点中的 14 条 DMA 路径。图中的“BMem to VMem”和“Bmem to ICI”路径实际上是由单个计数器累积的共享路径,在工具中显示为“BMem to ICI/VMem”。发送到 ICI 的 DMA 是发送到远程 HBM 或 VMEM 的 DMA,而从/到 HIB 的 DMA 是从/到主机内存的 DMA。
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI