
This tool is currently only available in nightly builds.
目標
這項工具的目標是提供 TPU 系統效能的鳥瞰圖,讓效能分析師找出可能發生效能問題的系統部分。
以視覺化方式呈現晶片層級的使用率
如要使用這項工具,請在左側的「抽屜」中尋找「使用率檢視器」工具。這項工具會顯示 4 個長條圖,分別代表 TPU 晶片中 2 個 Tensor Node 的執行單元 (上方 2 個圖表) 和 DMA 路徑 (下方 2 個圖表) 使用率。
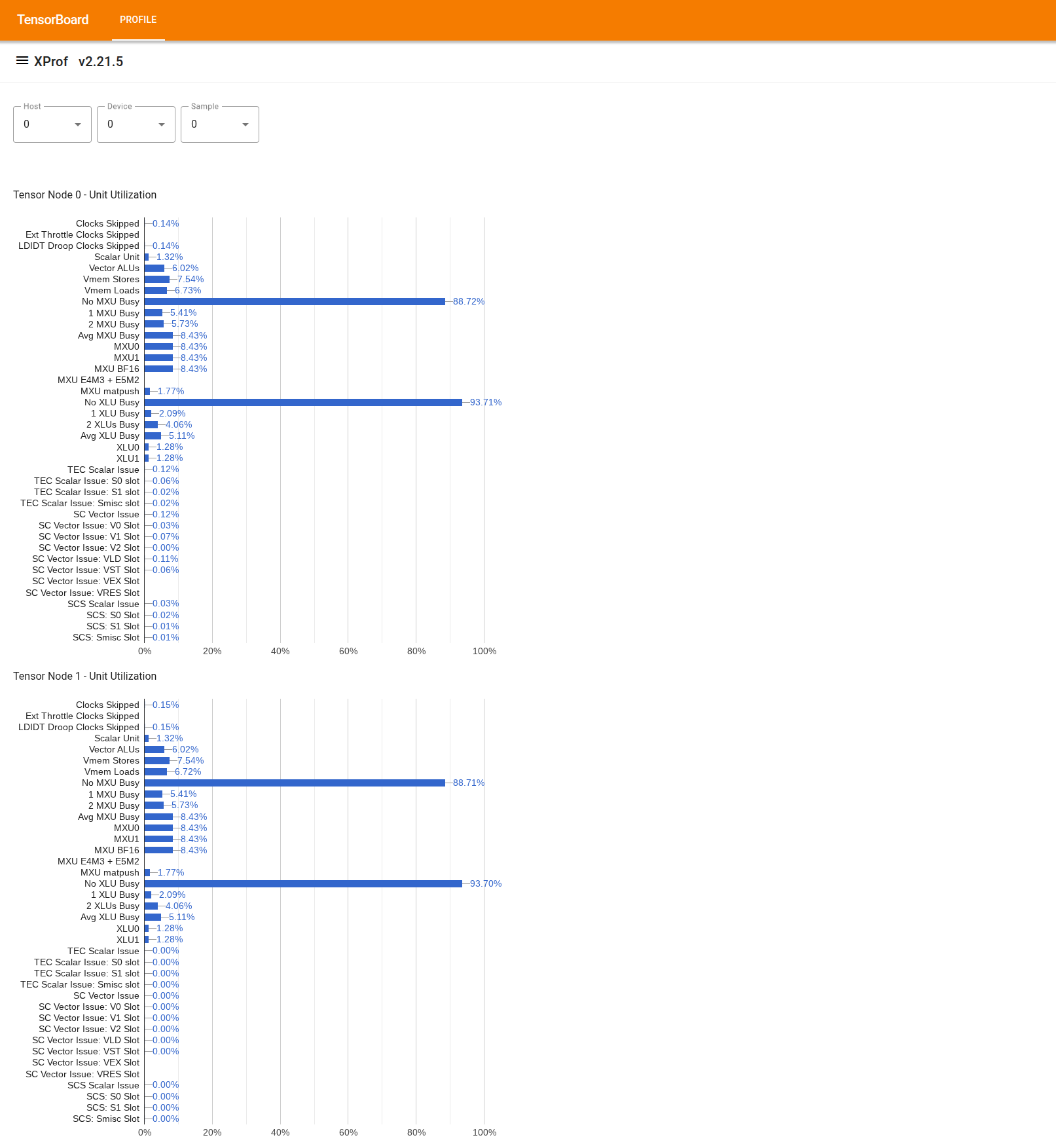
將游標懸停在長條上,工具提示會顯示使用率詳細資料:「已達成」和 (理論)「尖峰」數量。長條圖中顯示的使用率百分比,是將「達成」金額除以「最高」金額所得的結果。實際和尖峰用量會以「指令」為單位表示執行單元用量,並以「位元組」為單位表示頻寬用量。
執行單元的使用率是指在剖析期間內,單元忙碌的週期比例。
系統會顯示下列張量核心執行單元的利用率:
- 純量單元:計算方式為
count_s0_instruction和count_s1_instruction的總和,也就是純量指令的數量,除以週期數的兩倍,因為純量單元的輸送量為每個週期 2 個指令。 - 向量 ALU:計算方式為
count_v0_instruction和count_v1_instruction的總和,也就是向量指令數,再除以週期數的兩倍,因為向量 ALU 的處理量為每個週期 2 個指令。 - 向量儲存區:計算方式為
count_vector_store,也就是向量儲存區數量除以週期數,因為向量儲存區的處理量為每個週期 1 指令。 - 向量負載:計算方式為
count_vector_load,也就是向量負載數除以週期數,因為每個週期的向量負載輸送量為 1 指令。 - 矩陣單元 (MXU):計算方式為
count_matmul除以週期數的 1/8,因為 MXU 的輸送量為每 8 個週期 1 個指令。 - 轉置單元 (XU):計算方式為
count_transpose除以週期數的 1/8,因為 XU 輸送量為每 8 個週期 1 個指令。 - 縮減和排列單元 (RPU):計算方式為
count_rpu_instruction除以循環次數的 1/8,因為 RPU 總處理量為每 8 個週期 1 指令。
下圖是張量核心的方塊圖,顯示執行單元:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisible如要進一步瞭解這些執行單元,請參閱 TPU 架構。
- 純量單元:計算方式為
DMA 路徑使用率是指在剖析期間使用的頻寬比例 (位元組/週期)。這項指標是從 NF_CTRL 計數器衍生而來。
下圖顯示 7 個節點,代表 DMA 的來源 / 目的地,以及 Tensor 節點中的 14 個 DMA 路徑。圖中的「BMem to VMem」和「Bmem to ICI」路徑實際上是由單一計數器累積的共用路徑,在工具中顯示為「BMem to ICI/VMem」。傳送至 ICI 的 DMA 是傳送至遠端 HBM 或 VMEM 的 DMA,而從/至 HIB 的 DMA 則是從/至主機記憶體的 DMA。
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI