
This tool is currently only available in nightly builds.
الهدف
تهدف هذه الأداة إلى تقديم نظرة عامة على أداء نظام TPU والسماح لمحلّل الأداء برصد أجزاء النظام التي قد تواجه مشاكل في الأداء.
تصوُّر استخدام وحدة المعالجة المركزية على مستوى الشريحة
لاستخدام الأداة، ابحث عن "عارض الاستخدام" في "الدرج" على يمين الصفحة. تعرض الأداة 4 رسومات بيانية شريطية توضّح استخدام وحدات التنفيذ (أهم رسمَين بيانيَين) ومسارات الوصول المباشر إلى الذاكرة (DMA) (أهم رسمَين بيانيَين) لعقدتَي Tensor في شريحة TPU.
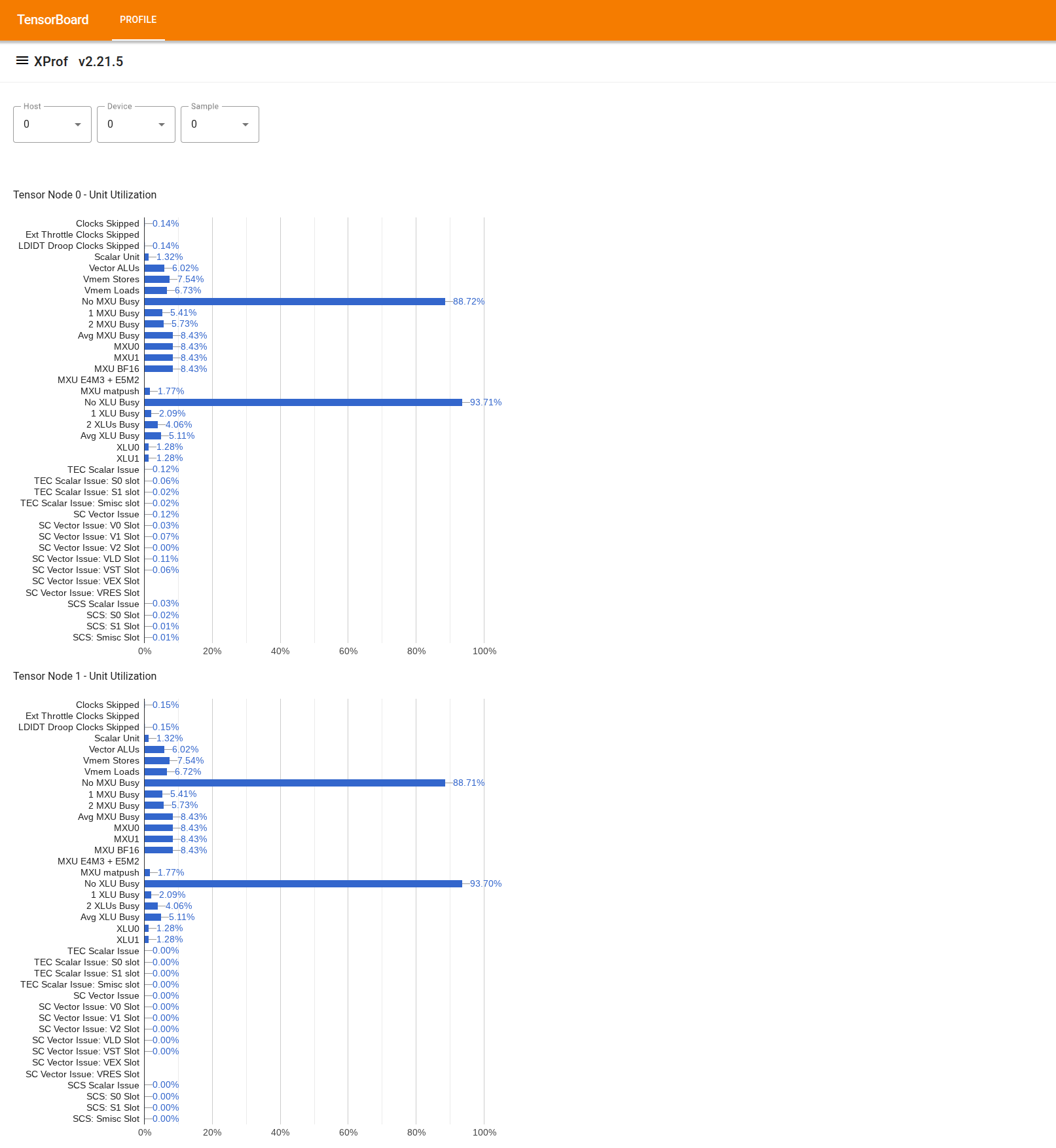
عند تمرير مؤشر الماوس فوق أحد الأشرطة، يظهر تلميح يتضمّن تفاصيل حول الاستخدام: الكميات "المحقّقة" و"القصوى" (النظرية). يتم الحصول على النسبة المئوية للاستخدام المعروضة في الشريط من خلال قسمة المبلغ "المحقّق" على المبلغ "الأقصى". يتم التعبير عن الكميات التي تم تحقيقها والكميات القصوى بوحدات التعليمات لاستخدام وحدة التنفيذ، وبايت لاستخدام النطاق الترددي.
يشير استخدام وحدة التنفيذ إلى جزء الدورات التي كانت الوحدة مشغولة بها خلال فترة إنشاء الملف الشخصي.
يتم عرض استخدام وحدات تنفيذ Tensor Core التالية:
- وحدة الأعداد القياسية: يتم احتسابها على النحو التالي: مجموع
count_s0_instructionوcount_s1_instruction، أي عدد تعليمات الأعداد القياسية، مقسومًا على ضعف عدد الدورات، لأنّ معدّل نقل البيانات لوحدة الأعداد القياسية هو تعليمتان لكل دورة. - وحدات ALU المتجهة: يتم احتسابها كمجموع
count_v0_instructionوcount_v1_instruction، أي عدد التعليمات المتجهة، مقسومًا على ضعف عدد الدورات، لأنّ معدّل نقل البيانات لوحدات ALU المتجهة هو تعليمتان لكل دورة. - مخازن المتجهات: يتم احتسابها على النحو التالي:
count_vector_store، أي عدد مخازن المتجهات مقسومًا على عدد الدورات، لأنّ معدّل نقل البيانات في مخزن المتجهات هو أمر واحد لكل دورة. - عمليات تحميل المتجهات: يتم احتسابها على النحو التالي:
count_vector_load، أي عدد عمليات تحميل المتجهات مقسومًا على عدد الدورات، لأنّ معدّل نقل البيانات لعمليات تحميل المتجهات هو أمر واحد لكل دورة. - وحدة المصفوفة (MXU): يتم احتسابها على النحو التالي:
count_matmulمقسومًا على ثُمن عدد الدورات، لأنّ معدّل نقل البيانات لوحدة المصفوفة هو أمر واحد لكل 8 دورات. - وحدة التبديل (XU): يتم احتسابها على النحو التالي:
count_transposeمقسومًا على ثُمن عدد الدورات، لأنّ معدّل نقل البيانات لوحدة التبديل هو أمر واحد لكل 8 دورات. - وحدة الاختزال والتبديل (RPU): يتم احتسابها على النحو التالي:
count_rpu_instructionمقسومًا على ثُمن عدد الدورات، لأنّ معدّل نقل البيانات لوحدة الاختزال والتبديل هو أمر واحد لكل 8 دورات.
الشكل التالي هو مخطط توضيحي لـ Tensor Core يعرض وحدات التنفيذ:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleلمزيد من التفاصيل حول كل وحدة من وحدات التنفيذ هذه، يُرجى الرجوع إلى بنية وحدة معالجة Tensor.
- وحدة الأعداد القياسية: يتم احتسابها على النحو التالي: مجموع
يشير استخدام مسارات DMA إلى جزء النطاق الترددي (بايت/دورة) الذي تم استخدامه خلال فترة تحديد الملف الشخصي. ويتم استخراجه من عدادات NF_CTRL.
يعرض الشكل التالي 7 عُقد تمثّل مصادر / وجهات مناطق السوق المحدّدة، و14 مسارًا لمنطقة السوق المحدّدة في "عقدة Tensor". إنّ المسارَين "BMem إلى VMem" و "Bmem إلى ICI" في الشكل هما في الواقع مسار مشترك يتم تجميعه بواسطة عدّاد واحد، ويظهران على أنّهما "BMem إلى ICI/VMem" في الأداة. إنّ عملية الوصول المباشر إلى الذاكرة (DMA) التي يتم إرسالها إلى واجهة ICI هي عملية وصول مباشر إلى الذاكرة إلى ذاكرة HBM أو VMEM بعيدة، بينما عملية الوصول المباشر إلى الذاكرة (DMA) من/إلى واجهة HIB هي عملية وصول مباشر إلى الذاكرة من/إلى ذاكرة المضيف.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI