
This tool is currently only available in nightly builds.
Obiettivo
Lo scopo di questo strumento è fornire una panoramica del rendimento di un sistema TPU e consentire a un analista delle prestazioni di individuare le parti del sistema che potrebbero presentare problemi di rendimento.
Visualizzare l'utilizzo a livello di chip
Per utilizzare lo strumento, cerca "Visualizzatore utilizzo" nel "Drawer" a sinistra. Lo strumento mostra quattro grafici a barre che indicano l'utilizzo delle unità di esecuzione e dei percorsi DMA per i due nodi Tensor in un chip TPU.
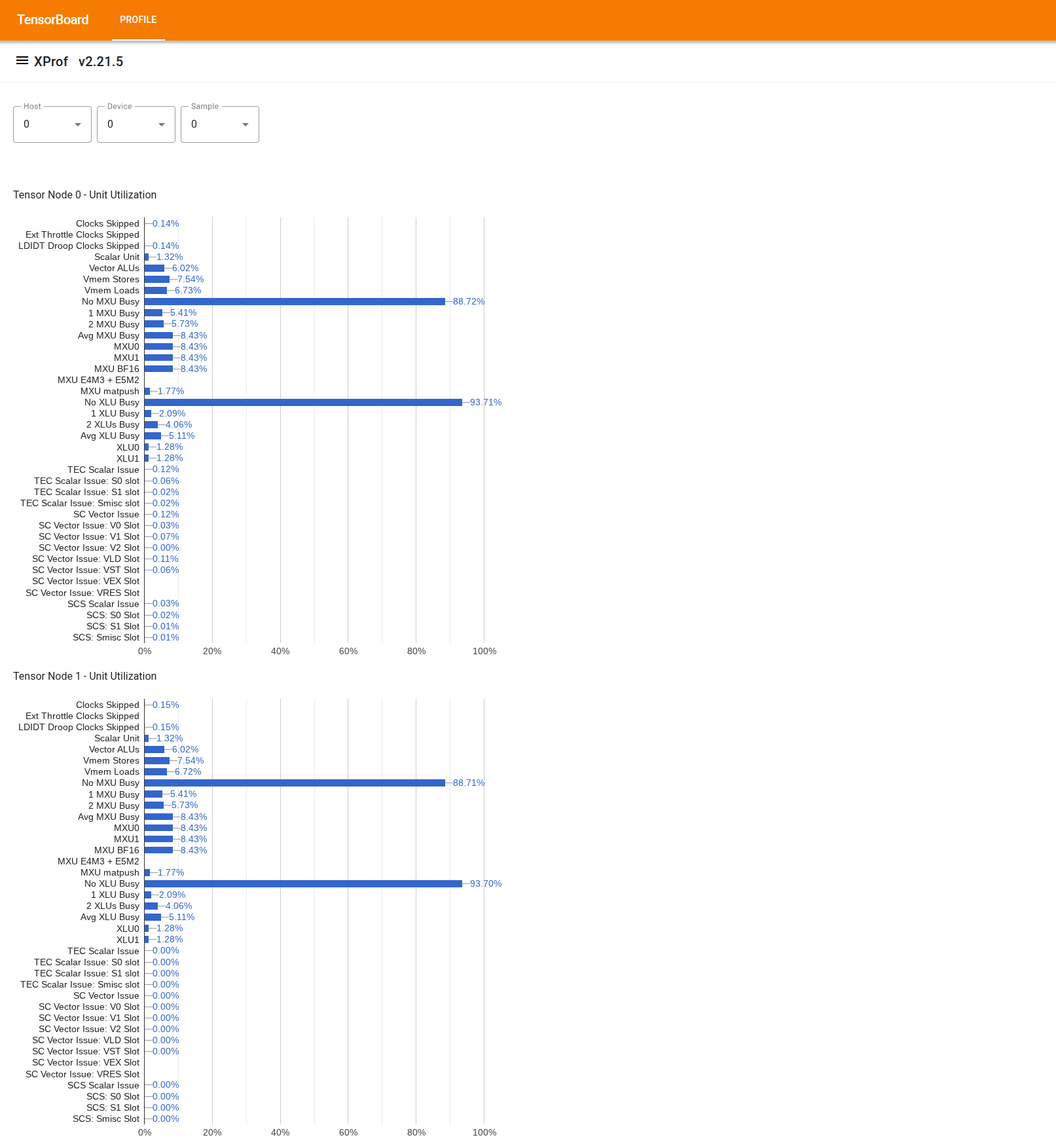
Se passi il mouse sopra una barra, viene visualizzata una descrizione comando con i dettagli sull'utilizzo: gli importi "raggiunti" e "di picco" (teorici). La percentuale di utilizzo mostrata nella barra si ottiene dividendo l'importo "raggiunto" per l'importo "picco". Gli importi raggiunti e di picco sono espressi in unità di istruzioni per l'utilizzo dell'unità di esecuzione e in byte per l'utilizzo della larghezza di banda.
L'utilizzo di un'unità di esecuzione è la frazione di cicli in cui l'unità è stata occupata nel periodo di profilazione.
Viene mostrato l'utilizzo delle seguenti unità di esecuzione Tensor Core:
- Unità scalare: calcolata come la somma di
count_s0_instructionecount_s1_instruction, ovvero il numero di istruzioni scalari, diviso per il doppio del numero di cicli, perché il throughput dell'unità scalare è di 2 istruzioni per ciclo. - ALU vettoriali: calcolate come somma di
count_v0_instructionecount_v1_instruction, ovvero il numero di istruzioni vettoriali, diviso per il doppio del numero di cicli, perché il throughput delle ALU vettoriali è di 2 istruzioni per ciclo. - Vector Stores: calcolato come
count_vector_store, ovvero il numero di vector store diviso per il numero di cicli, perché il throughput del vector store è di 1 istruzione per ciclo. - Caricamenti vettoriali: calcolati come
count_vector_load, ovvero il numero di caricamenti vettoriali diviso per il numero di cicli, perché la velocità effettiva di caricamento vettoriale è di un'istruzione per ciclo. - Unità di moltiplicazione a matrice (MXU): calcolata come
count_matmuldiviso per 1/8 del numero di cicli, perché la velocità effettiva della MXU è di 1 istruzione ogni 8 cicli. - Unità di trasposizione (XU): calcolata come
count_transposediviso per 1/8 del numero di cicli, perché la velocità effettiva dell'XU è di 1 istruzione ogni 8 cicli. - Unità di riduzione e permutazione (RPU): calcolata come
count_rpu_instructiondiviso per 1/8 del numero di cicli, perché il throughput della RPU è di 1 istruzione ogni 8 cicli.
La figura seguente è un diagramma a blocchi del Tensor Core che mostra le unità di esecuzione:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisiblePer maggiori dettagli su ciascuna di queste unità di esecuzione, consulta Architettura TPU.
- Unità scalare: calcolata come la somma di
L'utilizzo dei percorsi DMA è la frazione di larghezza di banda (byte/ciclo) utilizzata durante il periodo di profilazione. Deriva dai contatori NF_CTRL.
La figura seguente mostra 7 nodi che rappresentano le origini / destinazioni dei DMA e i 14 percorsi DMA in un nodo tensore. I percorsi "BMem to VMem" e "Bmem to ICI" nella figura sono in realtà un percorso condiviso accumulato da un singolo contatore, mostrato come "BMem to ICI/VMem" nello strumento. Un DMA inviato a ICI è un DMA a una HBM o VMEM remota, mentre un DMA da/a HIB è un DMA da/a memoria host.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI