
This tool is currently only available in nightly builds.
目標
このツールの目的は、TPU システムのパフォーマンスの概要を提供し、パフォーマンス アナリストがパフォーマンスの問題が発生している可能性のあるシステムの部分を特定できるようにすることです。
チップレベルの使用率を可視化する
このツールを使用するには、左側の [Drawer] で [Utilization Viewer] ツールを探します。このツールには、TPU チップの 2 つの Tensor ノードの実行ユニット(上部の 2 つのグラフ)と DMA パス(下部の 2 つのグラフ)の使用率を示す 4 つの棒グラフが表示されます。
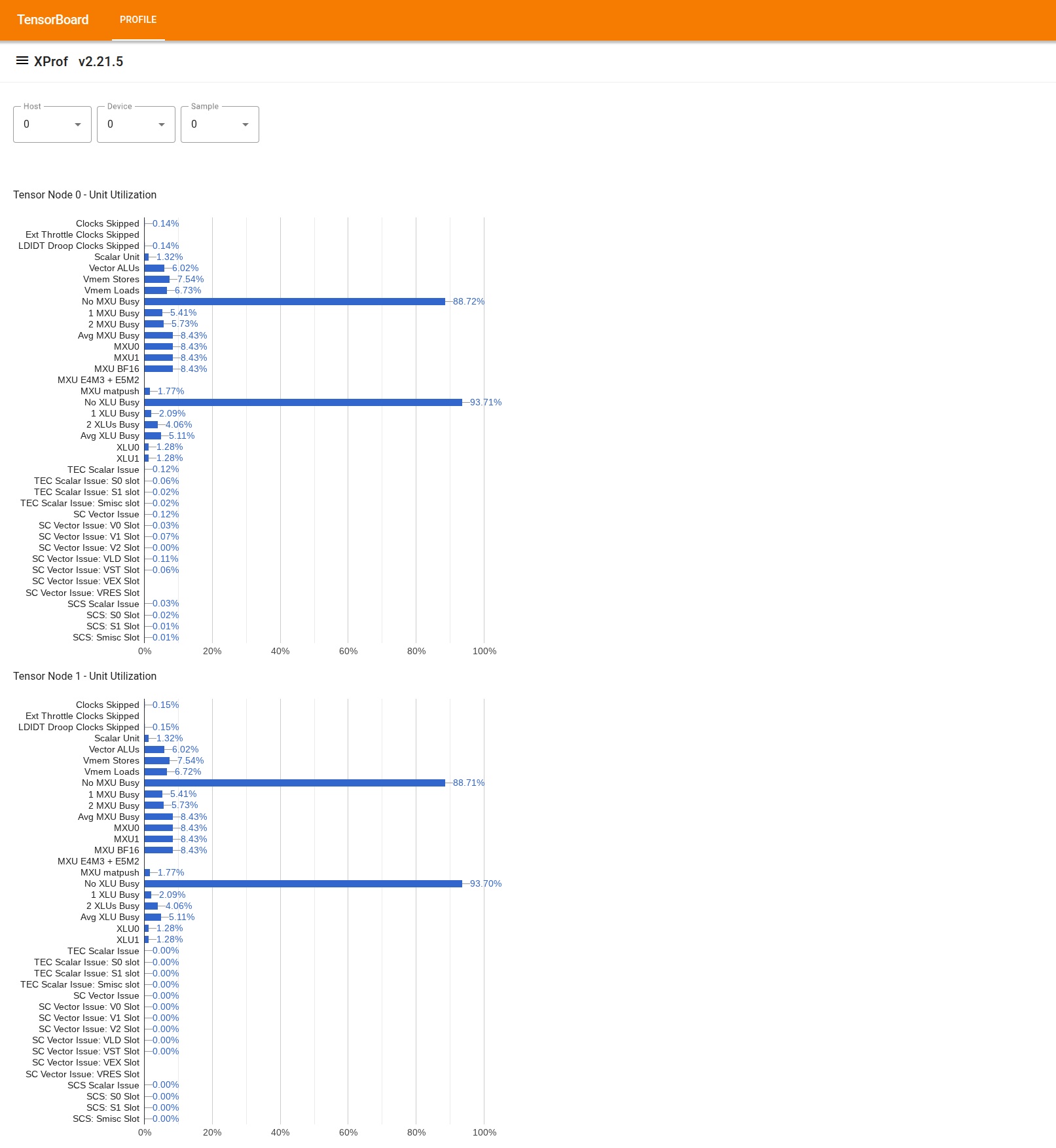
バーにカーソルを合わせると、使用率(達成値と(理論上の)ピーク値)の詳細を示すツールチップが表示されます。バーに表示される使用率は、「達成」額を「ピーク」額で割って求められます。達成量とピーク量は、実行ユニット使用率の場合は命令の単位で、帯域幅使用率の場合はバイトの単位で表されます。
実行ユニットの使用率は、プロファイリング期間内にユニットがビジー状態だったサイクルの割合です。
次のテンソルコア実行ユニットの使用率が表示されます。
- スカラー ユニット:
count_s0_instructionとcount_s1_instructionの合計として計算されます。つまり、スカラー ユニットのスループットはサイクルあたり 2 つの命令であるため、スカラー命令の数をサイクルの数の 2 倍で割った値です。 - ベクトル ALU:
count_v0_instructionとcount_v1_instructionの合計(ベクトル命令の数)を、サイクル数の 2 倍で割った値として計算されます。これは、ベクトル ALU のスループットが 1 サイクルあたり 2 つの命令であるためです。 - ベクトル ストア:
count_vector_storeとして計算されます。つまり、ベクトル ストアのスループットはサイクルあたり 1 命令であるため、ベクトル ストアの数をサイクル数で割った値です。 - ベクトル読み込み: ベクトル読み込みのスループットはサイクルあたり 1 命令であるため、
count_vector_load(ベクトル読み込みの数 / サイクル数)として計算されます。 - 行列ユニット(MXU): MXU のスループットは 8 サイクルあたり 1 命令であるため、
count_matmulをサイクル数の 1/8 で割った値として計算されます。 - 転置ユニット(XU): XU のスループットは 8 サイクルあたり 1 命令であるため、
count_transposeをサイクル数の 1/8 で割った値として計算されます。 - 削減と置換ユニット(RPU): RPU スループットは 8 サイクルあたり 1 命令であるため、
count_rpu_instructionをサイクル数の 1/8 で割った値として計算されます。
次の図は、実行ユニットを示すテンソルコアのブロック図です。
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleこれらの各実行ユニットの詳細については、TPU アーキテクチャをご覧ください。
- スカラー ユニット:
DMA パスの使用率は、プロファイリング期間中に使用された帯域幅の割合(バイト/サイクル)です。これは NF_CTRL カウンタから取得されます。
次の図は、DMA の送信元 / 送信先を表す 7 つのノードと、Tensor ノード内の 14 個の DMA パスを示しています。図の「BMem to VMem」と「Bmem to ICI」のパスは、実際には単一のカウンタによって累積された共有パスであり、ツールでは「BMem to ICI/VMem」と表示されます。ICI に送信される DMA はリモート HBM または VMEM への DMA であり、HIB から/への DMA はホストメモリから/への DMA です。
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI