
This tool is currently only available in nightly builds.
Hedef
Bu aracın amacı, bir TPU sisteminin performansına genel bir bakış sunmak ve bir performans analistinin, sistemin performans sorunları yaşayabilecek kısımlarını tespit etmesine olanak tanımaktır.
Çip düzeyinde kullanımı görselleştirme
Aracı kullanmak için soldaki "Çekmece" bölümünde "Kullanım Görüntüleyici" aracını bulun. Araç, bir TPU çipindeki 2 Tensor düğümü için yürütme birimlerinin (üstteki 2 grafik) ve DMA yollarının (alttaki 2 grafik) kullanımını gösteren 4 çubuk grafik görüntüler.
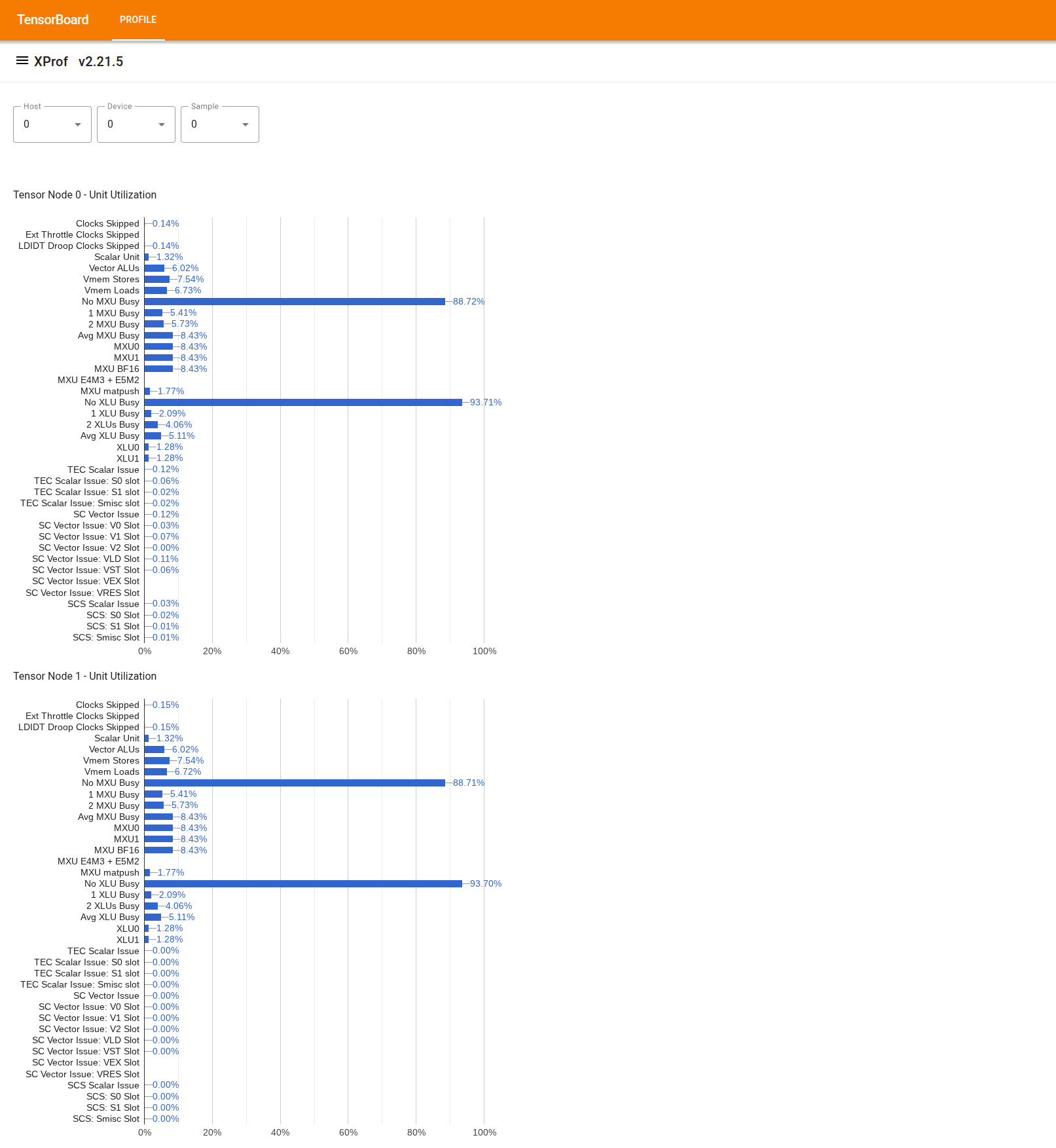
Bir çubuğun üzerine gelindiğinde, kullanım ayrıntılarını içeren bir ipucu gösterilir: "Ulaşılan" ve (teorik) "en yüksek" miktarlar. Çubukta gösterilen kullanım yüzdesi, "ulaşılan" tutarın "zirve" tutara bölünmesiyle elde edilir. Elde edilen ve en yüksek miktarlar, yürütme birimi kullanımı için talimat birimleriyle, bant genişliği kullanımı için ise bayt birimleriyle ifade edilir.
Yürütme biriminin kullanımı, profil oluşturma döneminde birimin meşgul olduğu döngülerin oranıdır.
Aşağıdaki tensör çekirdeği yürütme birimlerinin kullanımı gösterilir:
- Skaler birim:
count_s0_instructionvecount_s1_instructiontoplamı olarak hesaplanır. Yani skaler birim işleme hızı döngü başına 2 talimat olduğundan, skaler talimat sayısı döngü sayısının iki katına bölünür. - Vektör ALU'ları:
count_v0_instructionvecount_v1_instructiontoplamı olarak hesaplanır. Yani vektör ALU'larının işleme hızı döngü başına 2 talimat olduğundan, vektör talimatlarının sayısı döngü sayısının iki katına bölünür. - Vektör depoları: Vektör deposu işleme hızı döngü başına 1 talimat olduğundan
count_vector_storeolarak hesaplanır. Yani vektör deposu sayısı, döngü sayısına bölünür. - Vektör Yüklemeleri: Vektör yükleme işleme hızı döngü başına 1 talimat olduğundan,
count_vector_loadolarak hesaplanır. Yani vektör yükleme sayısı, döngü sayısına bölünür. - Matris Birimi (MXU): MXU işleme hızı 8 döngüde 1 talimat olduğundan
count_matmul, döngü sayısının 1/8'ine bölünerek hesaplanır. - Transpoze Birimi (XU): XU işleme hızı 8 döngüde 1 talimat olduğundan
count_transposedöngü sayısının 1/8'i olarak hesaplanır. - İndirgeme ve Permütasyon Birimi (RPU): RPU işleme hızı 8 döngüde 1 talimat olduğundan,
count_rpu_instructiondeğerinin döngü sayısının 1/8'ine bölünmesiyle hesaplanır.
Aşağıdaki şekil, yürütme birimlerini gösteren tensör çekirdeğinin blok şemasıdır:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleBu yürütme birimlerinin her biri hakkında daha fazla bilgi için lütfen TPU mimarisi başlıklı makaleyi inceleyin.
- Skaler birim:
DMA yollarının kullanımı, profilleme süresi boyunca kullanılan bant genişliği oranıdır (bayt/döngü). NF_CTRL sayaçlarından elde edilir.
Aşağıdaki şekilde, TPA'ların kaynaklarını / hedeflerini temsil eden 7 düğüm ve bir Tensor düğümündeki 14 TPA yolu gösterilmektedir. Şekildeki "BMem to VMem" ve "Bmem to ICI" yolları aslında tek bir sayaç tarafından biriktirilen ortak bir yoldur ve araçta "BMem to ICI/VMem" olarak gösterilir. ICI'ye gönderilen bir DMA, uzak bir HBM veya VMEM'ye gönderilen bir DMA'dır. HIB'den/HIB'e gönderilen bir DMA ise ana makine belleğinden/belleğine gönderilen bir DMA'dır.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI