
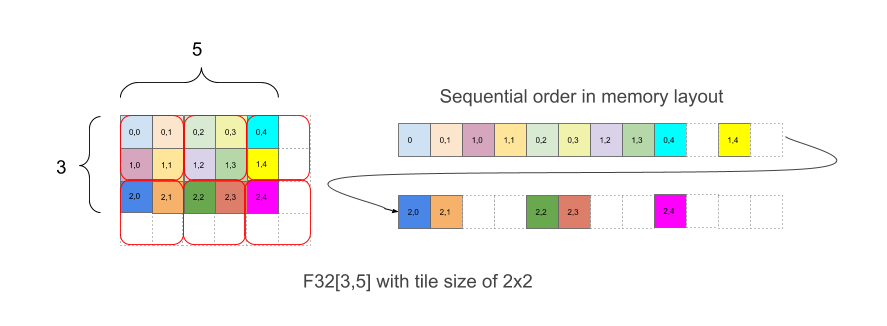
Figura 1
A figura 1 mostra como uma matriz F32[3,5] é disposta na memória com blocos 2x2. Uma
forma com esse layout é escrita como F32[3,5]{1,0:T(2,2)}, em que 1,0 se refere à
ordem física das dimensões (campo minor_to_major no layout), enquanto (2,2)
depois dos dois-pontos indica o agrupamento das dimensões físicas por um bloco 2x2.
Intuitivamente, os blocos são dispostos para cobrir a forma e, dentro de cada bloco, os elementos são dispostos sem blocos, como no exemplo acima, em que a parte direita mostra o layout na memória, incluindo os elementos de padding brancos que são adicionados para ter blocos 2x2 completos, mesmo que os limites originais da matriz não sejam uniformes.
Os elementos extras no padding não precisam conter nenhum valor específico.
Fórmulas de índice linear para agrupamento com base em uma forma e um bloco
Sem agrupamento, um elemento e=(en, en-1, ... , e1) em uma matriz com limites de matriz d=(dn, dn-1, ... , d1) (d1 é a dimensão mais secundária) é disposto na ordem maior para menor na posição:
linear_index(e, d)
= linear_index((en, en-1, ... , e1),
(dn, dn-1, ... , d1))
= endn-1...d1 +
en-1dn-2
Para simplificar a notação neste documento, presumimos que um bloco tem o mesmo número de dimensões que a matriz. Na implementação do XLA de agrupamento, isso é generalizado para blocos com menos dimensões, deixando as dimensões mais principais inicial inalteradas e aplicando o agrupamento apenas às dimensões mais secundárias, para que o agrupamento especificado mencione um sufixo das dimensões físicas da forma que está sendo lado a lado.
Quando o agrupamento de tamanho (tn, tn-1, ... , t1) é usado, um elemento na matriz com índices (en, en-1, ... , e1) é mapeado para esta posição no layout final:
n
O layout pode ser considerado como tendo duas partes: (⌊en/tn⌋, ... , ⌊e1/t1⌋), que corresponde a um índice de blocos em uma matriz de blocos de tamanho (⌈dn/tn⌉, ... , ⌈d1/ A função ceil aparece em ⌈di/ti⌉ porque, se os blocos ultrapassarem os limites da matriz maior, o preenchimento será inserido como na Figura 1. Os blocos e os elementos dentro deles são dispostos de forma recursiva, sem blocos.
No exemplo da Figura 1, o elemento (2,3) tem um índice de blocos (1,1) e um índice de bloco (0,1) para um vetor de coordenadas combinado de (1,1,0,1). Os índices de blocos têm limites (2,3) e o próprio bloco é (2,2) para um vetor combinado de (2,3,2,2). O índice linear com bloco para o elemento com índice (2,3) na forma lógica é então
índice_linear_com_tile((2,3), (3,5), (2,2))
= índice_linear((1,1,0,1), (2,3,2,2))
= índice_linear((1,1), (2,3)) ∙ 2 ∙ 2 + índice_linear((0,1), (2,2) +
Divisão como pad-reshape-transposição
O layout baseado em blocos funciona da seguinte maneira:
Considere uma matriz de dimensões (dn, dn-1, ... , d1) (d1
é a dimensão mais secundária). Quando ele é disposto com blocos de tamanho
(tn, tn-1, ... , t1) (t1 é a dimensão mais
menor), ele pode ser descrito em termos de pad-reshape-transpose
da seguinte maneira.
- A matriz é preenchida com (⌈dn/tn⌉∙tn, ... , ⌈d1/t1⌉∙t1).
- Cada dimensão i é dividida em (⌈di/ti⌉,
ti), ou seja, a matriz é remodelada para
(⌈dn/tn⌉, tn, ... , ⌈d1/t1⌉, t1).
Não há mudança física de layout nessa remodelação por si só, então essa remodelação é um bitcast. Se não estiver pensando explicitamente em um bloco, essa reforma poderá expressar qualquer forma com o mesmo número de elementos que a forma preenchida. Este exemplo mostra como expressar um bloco dessa maneira. - Uma transposição acontece movendo tn, ... , t1 para as dimensões mais secundárias, mantendo sua ordem relativa, de modo que a ordem das dimensões da maior para a menor se torne
(⌈dn/tn⌉, ... , ⌈d1/t1⌉, tn, tn).
A forma final tem o prefixo
(⌈dn/tn⌉, ... ,
⌈d1/t1⌉), que descreve o número de blocos em cada
dimensão. Um elemento na matriz (en, ... , e1) é
mapeado para esse elemento na forma final:
(⌊en/tn⌋, ... ,
⌊e0/t0⌋, en mod tn, ... ,
e1 ). É fácil ver que o índice linear do
elemento segue a fórmula acima, como esperado.
Blocos repetidos
O agrupamento do XLA se torna ainda mais flexível ao aplicá-lo repetidamente.
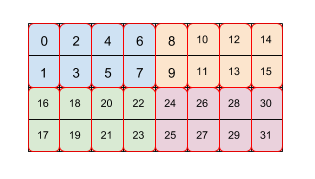
Figura 2
A Figura 2 mostra como uma matriz de tamanho 4x8 é dividida em dois níveis (primeiro 2x4, depois 2x1). Representamos esse agrupamento repetido como (2,4)(2,1). Cada cor indica um bloco de 2x4, e cada caixa de borda vermelha é um bloco de 2x1. Os números indicam o índice linear na memória desse elemento no formato lado a lado. Esse formato corresponde ao formato usado para BF16 na TPU, exceto pelo fato de o bloco inicial ser maior, ou seja,o bloco é (8.128)(2,1), em que a finalidade do segundo bloco por 2x1 é coletar dois valores de 16 bits para formar um valor de 32 bits de forma alinhada com a arquitetura de uma TPU.
Um segundo bloco ou um mais recente pode se referir às dimensões secundárias do bloco, que apenas reorganizam os dados dentro do bloco, como neste exemplo com (8.128)(2,1), mas também pode se referir às principais dimensões de bloco cruzado do bloco anterior.
Combinar dimensões usando blocos
O agrupamento do XLA também permite a combinação de dimensões. Por exemplo, ele pode combinar dimensões em F32[2,7,8,11,10]{4,3,2,1,0} para F32[112,110]{1,0} antes de juntá-lo com (2,3). O bloco usado é (∗,∗,2,*,3). Aqui, um asterisco em um bloco implica tomar essa dimensão e combiná-la com a próxima dimensão menor. Várias dimensões adjacentes podem ser somadas em uma dimensão. Uma dimensão subsumida é representada por um valor de -1 nessa dimensão do bloco, que não é válida em um bloco como um tamanho de dimensão.
Mais precisamente, se a dimensão i da forma for eliminada por um asterisco no bloco, antes da aplicação da definição anterior de bloco, essa dimensão será removida da forma que está sendo dividida e do vetor do bloco, e o limite da matriz i-1 da forma terá um limite de matriz aumentado de di-1 para didi-1. Essa etapa é repetida para cada asterisco no vetor de bloco.