
बैकग्राउंड
शीयरिंग के तरीके से यह तय किया जाता है कि उपलब्ध डिवाइसों के सेट के हिसाब से, टेंसर को कैसे शीयर किया जाए.
डेटा का बंटवारा इनमें से किसी भी तरीके से किया जा सकता है:
- उपयोगकर्ता ने इनपुट, आउटपुट या इंटरमीडिएट पर, शार्डिंग की पाबंदियों के तौर पर मैन्युअल तौर पर तय किया है.
- शर्डिंग प्रॉपेगेशन की प्रोसेस में, हर कार्रवाई के हिसाब से बदला जाता है.
खास जानकारी
बुनियादी स्ट्रक्चर
लॉजिकल मेश, डिवाइसों का एक मल्टी-डाइमेंशनल व्यू होता है. इसे ऐक्सिस के नाम और साइज़ की सूची से तय किया जाता है.
सुझाई गई sharding का प्रतिनिधित्व, नाम के हिसाब से किसी खास लॉजिकल मेश से जुड़ा होता है. साथ ही, उस मेश से सिर्फ़ ऐक्सिस के नाम का रेफ़रंस दिया जा सकता है. टेंसर को अलग-अलग हिस्सों में बांटने से यह पता चलता है कि किसी खास लॉजिकल मेश के किन ऐक्सिस के हिसाब से, टेंसर के हर डाइमेंशन को अलग-अलग हिस्सों में बांटा गया है. टेंसर को मेश के सभी अन्य ऐक्सिस के साथ दोहराया जाता है.
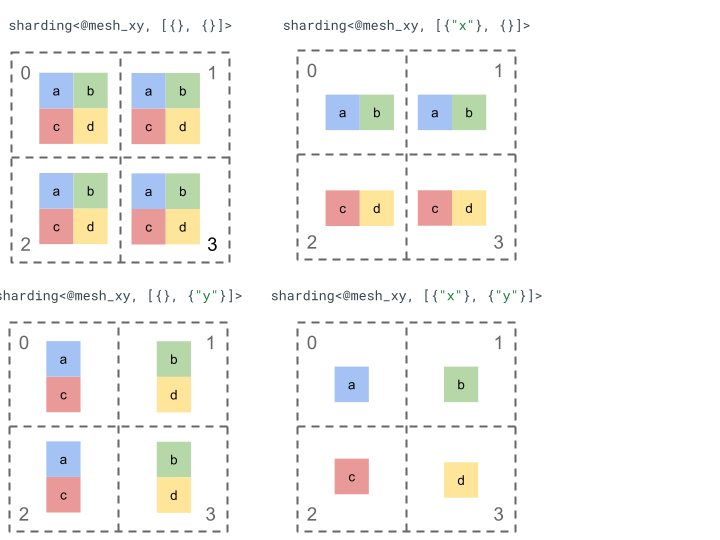
आइए, रैंक 2 के एक आसान टेंसर और चार डिवाइसों के साथ, शीयरिंग के तरीके को एक्सप्लोर करें.
हम सबसे पहले चार डिवाइसों [0, 1, 2, 3] को दो डाइमेंशन वाले ऐरे [[0, 1], [2,
3]] में बदल देते हैं, ताकि दो ऐक्सिस वाला मेश बनाया जा सके:
@mesh_xy = <["x"=2, "y"=2]>
इसके बाद, हम रैंक 2 के इस टेंसर [[a, b], [c, d]] को इस तरह से शर्ड कर सकते हैं:
अन्य मुख्य कॉम्पोनेंट
- ओपन/क्लोज़्ड डाइमेंशन - डाइमेंशन या तो ओपन हो सकते हैं - उपलब्ध ऐक्सिस पर आगे भी शर्ड किए जा सकते हैं या क्लोज़्ड हो सकते हैं - ये तय होते हैं और इनमें बदलाव नहीं किया जा सकता.
- एक्सप्लिसिट तौर पर डुप्लीकेट किए गए ऐक्सिस - जिन ऐक्सिस का इस्तेमाल किसी डाइमेंशन को शेयर करने के लिए नहीं किया जाता उन्हें डिफ़ॉल्ट रूप से डुप्लीकेट किया जाता है. हालांकि, शेयर करने की सुविधा में उन ऐक्सिस को शामिल किया जा सकता है जिन्हें एक्सप्लिसिट तौर पर डुप्लीकेट किया गया है. इसलिए, बाद में किसी डाइमेंशन को शेयर करने के लिए, उन ऐक्सिस का इस्तेमाल नहीं किया जा सकता.
- ऐक्सिस को अलग-अलग हिस्सों में बांटना और सब-ऐक्सिस - किसी (पूरे) मेश ऐक्सिस को कई सब-ऐक्सिस में बांटा जा सकता है. इनका इस्तेमाल, किसी डाइमेंशन को अलग-अलग हिस्सों में बांटने या साफ़ तौर पर डुप्लीकेट करने के लिए किया जा सकता है.
- एक से ज़्यादा लॉजिकल मेश - अलग-अलग शीयरिंग को अलग-अलग लॉजिकल मेश से जोड़ा जा सकता है. इनमें अलग-अलग ऐक्सिस या लॉजिकल डिवाइस आईडी का अलग क्रम भी हो सकता है.
- प्राथमिकताएं - किसी प्रोग्राम को धीरे-धीरे अलग-अलग हिस्सों में बांटने के लिए, डाइमेंशन के हिस्सों को प्राथमिकताएं दी जा सकती हैं. इससे यह तय होता है कि हर डाइमेंशन के हिस्सों की पाबंदियों को पूरे मॉड्यूल में किस क्रम में लागू किया जाएगा.
- डाइमेंशन को अलग-अलग हिस्सों में बांटने की सुविधा - डाइमेंशन को उन ऐक्सिस पर बांटा जा सकता है जिनके साइज़ का प्रॉडक्ट, डाइमेंशन के साइज़ को बांटता हो.
ज़्यादा जानकारी वाला डिज़ाइन
इस सेक्शन में, हम बुनियादी स्ट्रक्चर और हर मुख्य कॉम्पोनेंट के बारे में ज़्यादा जानकारी देते हैं.
बुनियादी स्ट्रक्चर
डाइमेंशन की शार्डिंग से हमें टेंसर के हर डाइमेंशन के लिए पता चलता है कि किन ऐक्सिस (या सब-ऐक्सिस) के साथ इसे मेजर से लेकर माइनर तक शार्ड किया गया है. ऐसे सभी दूसरे ऐक्सिस जिन्हें किसी डाइमेंशन के लिए, अलग-अलग हिस्सों में नहीं बांटा जाता है उन्हें अपने-आप डुप्लीकेट किया जाता है (या साफ़ तौर पर डुप्लीकेट किया जाता है).
हम एक आसान उदाहरण से शुरुआत करेंगे और अन्य सुविधाओं के बारे में बताते समय इसे बढ़ाएंगे.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st tensor dimension is sharded along axis "x" and the 2nd tensor dimension is
// sharded along axis "z" then further along axis "y". The local shape of this tensor (i.e. the shape on a single device), would be tensor<2x1xf32>.
sharding<@mesh_xy, [{"x"}, {"z", "y"}]> : tensor<4x8xf32>
इनवैरिएंट
- डाइमेंशन की शार्डिंग की संख्या, टेंसर की रैंक से मेल खानी चाहिए.
- रेफ़र किए गए मेश में सभी ऐक्सिस के नाम मौजूद होने चाहिए.
- ऐक्सिस या सब-ऐक्सिस, शीयरिंग के तरीके से दिखाए गए डेटा में सिर्फ़ एक बार दिख सकते हैं. हर ऐक्सिस, किसी डाइमेंशन को शीयर करता है या साफ़ तौर पर डुप्लीकेट किया जाता है.
ओपन/क्लोज़्ड डाइमेंशन
टेंसर का हर डाइमेंशन, ओपन या क्लोज़्ड हो सकता है.
खोलें
ओपन डाइमेंशन को अन्य ऐक्सिस के साथ शर्ड करने के लिए, प्रॉपेगेशन के लिए उपलब्ध कराया जाता है. इसका मतलब है कि तय किए गए डाइमेंशन को शर्ड करने का यह तरीका, उस डाइमेंशन को शर्ड करने का आखिरी तरीका नहीं होना चाहिए. यह जीएसपीएमडी के unspecified_dims से मिलता-जुलता है, लेकिन बिल्कुल एक जैसा नहीं है.
अगर कोई डाइमेंशन ओपन है, तो हम उन ऐक्सिस के बाद ? जोड़ते हैं जिन पर डाइमेंशन पहले से ही शेयर किया गया है (नीचे उदाहरण देखें).
बंद है
क्लोज़्ड डाइमेंशन वह होता है जिसे प्रोपेगेट करने के लिए, उसमें और शीयरिंग नहीं जोड़ी जा सकती. इसका मतलब है कि तय किए गए डाइमेंशन की शीयरिंग, उस डाइमेंशन की फ़ाइनल शीयरिंग होती है और इसे बदला नहीं जा सकता. इसका एक सामान्य इस्तेमाल का उदाहरण यह है कि GSPMD, आम तौर पर किसी मॉड्यूल के इनपुट/आउटपुट आर्ग्युमेंट में बदलाव कैसे नहीं करता या jax.jit के साथ, उपयोगकर्ता की बताई गई in_shardings स्टैटिक कैसे होती है - वे बदल नहीं सकतीं.
ऊपर दिए गए उदाहरण को बड़ा करके, ओपन डाइमेंशन और क्लोज़्ड डाइमेंशन बनाया जा सकता है.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st dimension is closed, therefore it can't be further sharded and {"x"}
// will remain its sharding. The 2nd dimension is open, and can therefore be
// further sharded during propagation, e.g. by "y".
sharding<@mesh_xy, [{"x"}, {"z", ?}]> : tensor<4x8xf32>
साफ़ तौर पर डुप्लीकेट किए गए ऐक्सिस
अक्षों का एक साफ़ तौर पर तय किया गया सेट, जिस पर टेंसर को दोहराया जाता है. हालांकि, यह तय किया जा सकता है कि किसी अक्ष पर बंटवारा न किए गए टेंसर को उस पर चुपचाप डुप्लीकेट किया गया है (जैसे कि आज jax.sharding.PartitionSpec), लेकिन साफ़ तौर पर बताने से यह पक्का होता है कि प्रॉपेगेशन, इन अक्षों का इस्तेमाल उन अक्षों के साथ किसी ओपन डाइमेंशन को और भी बंटवारे में नहीं कर सकता. इंप्लिसिट रिप्लिकेशन की मदद से, टेंसर को अलग-अलग हिस्सों में बांटा जा सकता है. हालांकि, साफ़ तौर पर डुप्लीकेट बनाने की सुविधा का इस्तेमाल करने पर, उस अक्ष के साथ टेंसर को कोई भी हिस्सा नहीं दिया जा सकता.
डुप्लीकेट किए गए ऐक्सिस के क्रम से, टेंसर के डेटा को सेव करने के तरीके पर कोई असर नहीं पड़ता. हालांकि, सिर्फ़ एक जैसा रखने के लिए, ऐक्सिस को उसी क्रम में सेव किया जाएगा जिस क्रम में उन्हें टॉप लेवल मेश में बताया गया है. उदाहरण के लिए, अगर मेश:
@mesh_xy = <["c"=2, "a"=2, "b"=2]>
अगर हमें ऐक्सिस "a" और "c" को साफ़ तौर पर दोहराना है, तो ऑर्डर यह होना चाहिए:
replicated={"c", "a"}
ऊपर दिए गए उदाहरण को बड़ा करके, साफ़ तौर पर डुप्लीकेट किया गया ऐक्सिस बनाया जा सकता है.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// Since "y" is explicitly replicated, it can't be used to shard the 2nd
// dimension that is open. However, "z" is implicitly replicated so it can be
// used to shard that dimension. The local shape of this tensor (i.e. the
// shape on a single device), would be tensor<2x8xf32>.
sharding<@mesh_xyz, [{"x"}, {?}], replicated={"y"}> : tensor<4x8xf32>
ऐक्सिस को अलग-अलग करना और सब-ऐक्सिस
डिवाइसों के एक डाइमेंशन वाले ऐरे को n-डाइमेंशन वाले ऐरे में बदलकर, n ऐक्सिस का लॉजिकल मेश बनाया जाता है. इसमें हर डाइमेंशन, उपयोगकर्ता के तय किए गए नाम के साथ एक ऐक्सिस बनाता है.
कंपाइलर में भी यही प्रोसेस की जा सकती है. इससे, k साइज़ के ऐक्सिस को m सब-ऐक्सिस में बांटा जा सकता है. इसके लिए, मेश को [...,k,...] से [...,k1,...,km,...] में बदलना होगा.
वजह
अलग-अलग ऐक्सिस बनाने की वजह को समझने के लिए, हम नीचे दिए गए उदाहरण को देखेंगे:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 : (tensor<8xf32>) -> tensor<2x4xf32>
हम डेटा को फिर से शेप करने के नतीजे को इस तरह से शेयर करना चाहते हैं कि डेटा को एक से दूसरी जगह भेजने की ज़रूरत न पड़े. "x" का साइज़, नतीजे के पहले डाइमेंशन से ज़्यादा है. इसलिए, हमें ऐक्सिस को दो सब-ऐक्सिस "x.0" और "x.1" में बांटना होगा. दोनों का साइज़ दो होना चाहिए. साथ ही, पहले डाइमेंशन को "x.0" और दूसरे डाइमेंशन को "x.1" पर शर्ड करना होगा.
फ़ंक्शन के इनपुट/आउटपुट को अलग-अलग हिस्सों में बांटना
ऐसा हो सकता है कि प्रॉपेगेशन के दौरान, मुख्य फ़ंक्शन का इनपुट या आउटपुट, सब-ऐक्सिस के साथ शर्ड हो जाए. यह कुछ फ़्रेमवर्क के लिए समस्या हो सकती है, जहां हम उपयोगकर्ता को वापस देने के लिए, ऐसी शर्डिंग नहीं दिखा सकते. उदाहरण के लिए, JAX में हम jax.sharding.NamedSharding के साथ सब-ऐक्स नहीं दिखा सकते.
ऐसे मामलों में, हमारे पास कुछ विकल्प होते हैं:
- sharding को अनुमति दें और उसे किसी दूसरे फ़ॉर्मैट में दिखाएं. उदाहरण के लिए, JAX में
jax.sharding.NamedShardingके बजायjax.sharding.PositionalSharding. - इनपुट/आउटपुट को अलग-अलग हिस्सों में बांटने वाले सब-ऐक्स को अनुमति न दें और उन्हें इकट्ठा न करें.
फ़िलहाल, हम प्रॉपेगेशन पाइपलाइन में इनपुट/आउटपुट पर सब-ऐक्सिस की अनुमति देते हैं. अगर आपको इसे बंद करना है, तो हमें बताएं.
प्रतिनिधित्व
जिस तरह हम मेश से किसी खास ऐक्सिस का नाम बताकर उसका रेफ़रंस दे सकते हैं उसी तरह हम किसी खास सब-ऐक्सिस का रेफ़रंस उसके साइज़ और बाईं ओर मौजूद सभी सब-ऐक्सिस (एक ही ऐक्सिस के नाम के) के साइज़ के प्रॉडक्ट के हिसाब से दे सकते हैं.
n साइज़ की पूरी ऐक्सिस "x" से, k साइज़ की किसी खास सब-ऐक्सिस को निकालने के लिए,
हम मेश में n साइज़ को [m, k, n/(m*k)] में बदल देते हैं और दूसरे डाइमेंशन का इस्तेमाल सब-ऐक्सिस के तौर पर करते हैं. इसलिए, किसी सब-ऐक्सिस को दो संख्याओं, m और k से दिखाया जा सकता है. साथ ही, हम सब-ऐक्सिस को दिखाने के लिए, इस छोटे नोटेशन का इस्तेमाल करते हैं: "x":(m)k.
m>=1, इस सब-ऐक्सिस का प्री-साइज़ है.m,nका डिविज़र होना चाहिए. प्री-साइज़, इस सब-ऐक्सिस की बाईं ओर मौजूद सभी सब-ऐक्सिस साइज़ का प्रॉडक्ट होता है. अगर यह 1 के बराबर है, तो इसका मतलब है कि कोई सब-ऐक्सिस नहीं है. अगर यह 1 से ज़्यादा है, तो यह एक या एक से ज़्यादा सब-ऐक्सिस से जुड़ा होता है.k>1, इस सब-ऐक्सिस का असल साइज़ है.k,nका डिविज़र होना चाहिए.n/(m*k), पोस्ट का साइज़ है. यह इस सब-ऐक्सिस के दाईं ओर मौजूद सभी सब-ऐक्सिस के साइज़ का प्रॉडक्ट होता है. अगर यह 1 के बराबर है, तो इसका मतलब है कि कोई सब-ऐक्सिस नहीं है. अगर यह 1 से ज़्यादा है, तो यह एक या एक से ज़्यादा सब-ऐक्सिस से जुड़ा होता है.
हालांकि, किसी खास सब-ऐक्सिस "x":(m)k का इस्तेमाल करते समय, अन्य सब-ऐक्सिस की संख्या से कोई फ़र्क़ नहीं पड़ता. साथ ही, अगर कोई सब-ऐक्सिस किसी डाइमेंशन को शेयर नहीं करता है या साफ़ तौर पर डुप्लीकेट किया जाता है, तो टेंसर को शेयर करने के लिए, किसी अन्य सब-ऐक्सिस का रेफ़रंस देने की ज़रूरत नहीं होती.
मोटिवेशन सेक्शन में दिए गए उदाहरण पर वापस आकर, हम नतीजे को इस तरह से शेयर कर सकते हैं:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 {sdy.sharding_per_value=<[<@mesh_x, [{"x":(1)2}, {"x":(2)2}]>]>}
: (tensor<8xf32>) -> tensor<2x4xf32>
यहां स्प्लिट ऐक्सिस का एक और उदाहरण दिया गया है, जिसमें सिर्फ़ कुछ सब-ऐक्सिस का इस्तेमाल किया गया है.
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Axis "y" is effectively split into 3 sub-axes denoted as
// "y":(1)2, "y":(2)2, "y":(4)2
// in order, but only "y":(2)2 is used, to shard the 2nd dimension. The local
// shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x4xf32>.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}]> : tensor<4x8xf32>
इसी तरह, नीचे दी गई दो शर्डिंग एक जैसी हैं. mesh_xy को mesh_full के बंटवारे के तौर पर देखा जा सकता है.
@mesh_full = <"devices"=8>
@mesh_xy = <"x"=4, "y"=2>
sharding<@mesh_xy, [{"x"},{ "y"}]> : tensor<4x4xf32>
sharding<@mesh_full, [{"devices":(1)4}, {"devices":(4)2}]> : tensor<4x4xf32>
साफ़ तौर पर डुप्लीकेट किए गए सब-ऐक्सिस
डाइमेंशन को अलग-अलग हिस्सों में बांटने के लिए इस्तेमाल किए जा रहे सब-ऐक्सिस के अलावा, उन्हें साफ़ तौर पर डुप्लीकेट के तौर पर भी मार्क किया जा सकता है. हम डेटा को इस तरह दिखाने की अनुमति देते हैं, क्योंकि सब-ऐक्सिस, पूरी तरह के ऐक्सिस की तरह ही काम करते हैं.इसका मतलब है कि जब ऐक्सिस "x" के किसी सब-ऐक्सिस के साथ किसी डाइमेंशन को शेयर किया जाता है, तो "x" के अन्य सब-ऐक्सिस अपने-आप डुप्लीकेट हो जाते हैं. इसलिए, सब-ऐक्सिस को साफ़ तौर पर डुप्लीकेट किया जा सकता है, ताकि यह पता चल सके कि सब-ऐक्सिस को डुप्लीकेट किया जाना चाहिए और इसका इस्तेमाल किसी डाइमेंशन को शेयर करने के लिए नहीं किया जा सकता.
उदाहरण के लिए:
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Sub-axis "y":(1)2 is explicitly replicated and "y":(4)2 is implicitly replicated.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}], replicated={"y":(1)2}> : tensor<4x8xf32>
एक ही फ़ुल ऐक्सिस के डुप्लीकेट सब-ऐक्सिस को, उनके पहले साइज़ के हिसाब से बढ़ते क्रम में लगाया जाना चाहिए. उदाहरण के लिए:
replicated={"y":(4)2, "x", "y":(1)2} ~> replicated={"x", "y":(1)2, "y":(4)2}
इनवैरिएंट
टेंसर को अलग-अलग हिस्सों में बांटने के दौरान रेफ़र किए गए सब-ऐक्सिस ओवरलैप नहीं होने चाहिए. जैसे,
"x":(1)4और"x":(2)4ओवरलैप करते हैं.टेंसर को अलग-अलग हिस्सों में बांटने के दौरान रेफ़र किए गए सब-ऐक्सिस ज़्यादा से ज़्यादा बड़े होने चाहिए. इसका मतलब है कि अगर डाइमेंशन को अलग-अलग हिस्सों में बांटने के दौरान, एक-दूसरे के बगल में मौजूद दो सब-ऐक्सिस A और B हैं या सब-ऐक्सिस A और B को साफ़ तौर पर डुप्लीकेट किया गया है, तो वे एक-दूसरे के बगल में नहीं होने चाहिए. उदाहरण के लिए,
"x":(1)2और"x":(2)4, क्योंकि इन्हें एक"x":(1)8से बदला जा सकता है.
एक से ज़्यादा लॉजिकल मेश
एक लॉजिकल मेश, डिवाइसों का मल्टी-डाइमेंशनल व्यू होता है. शर्डिंग दिखाने के लिए, हमें डिवाइसों के कई व्यू की ज़रूरत पड़ सकती है. खास तौर पर, डिवाइसों को मनमुताबिक असाइन करने के लिए.
उदाहरण के लिए,
jax.sharding.PositionalSharding में एक सामान्य लॉजिकल मेश नहीं है.
फ़िलहाल, GSPMD में HloSharding की मदद से ऐसा किया जा सकता है. इसमें डिवाइसों और डाइमेंशन के साइज़ की क्रम से लगाई गई सूची दिखाई जा सकती है. हालांकि, इसे ऊपर बताए गए ऐक्सिस को बांटने की सुविधा से नहीं दिखाया जा सकता.
हम इस समस्या को हल करते हैं और प्रोग्राम के सबसे ऊपरी लेवल पर एक से ज़्यादा लॉजिकल मेश तय करके, मौजूदा कोने के मामलों को मैनेज करते हैं. हर मेश में, अलग-अलग नामों के साथ अलग-अलग संख्या में ऐक्सिस हो सकते हैं. साथ ही, डिवाइसों के एक ही सेट के लिए, अपने हिसाब से असाइनमेंट भी हो सकते हैं. इसका मतलब है कि हर मेश, डिवाइसों के एक ही सेट (उनके यूनीक लॉजिकल आईडी के हिसाब से) को दिखाता है, लेकिन किसी भी क्रम में. यह GSPMD के तौर पर दिखाए जाने वाले डेटा से मिलता-जुलता है.
हर शीयरिंग रिप्रज़ेंटेशन, किसी खास लॉजिकल मेश से जुड़ा होता है. इसलिए, यह सिर्फ़ उस मेश के ऐक्सिस का रेफ़रंस देगा.
किसी एक लॉजिकल मेश को असाइन किए गए टेंसर का इस्तेमाल, किसी ऐसे ऑपरेशन में किया जा सकता है जिसे किसी दूसरे मेश को असाइन किया गया हो. इसके लिए, डेस्टिनेशन मेश से मैच करने के लिए, टेंसर को फिर से रीशर्ड किया जाता है. आम तौर पर, GSPMD में, एक-दूसरे से मेल न खाने वाले मेश को ठीक करने के लिए ऐसा किया जाता है.
उपयोगकर्ता, अलग-अलग नाम वाले ऐक्सिस (उदाहरण के लिए, jax.sharding.NamedSharding के ज़रिए) के साथ कई मेश तय कर सकते हैं. इन मेश में डिवाइसों का क्रम एक जैसा होना चाहिए. इस उदाहरण पर विचार करें, <@mesh_0, "b"> और <@mesh_1, "z"> एक जैसे हैं:
@mesh_0 = {<["a"=4, "b"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
@mesh_1 = {<["x"=2, "y"=2, "z"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
प्राथमिकताएं
प्राथमिकता, कुछ पार्टिशनिंग और प्रॉपेगेशन के फ़ैसलों को दूसरों के मुकाबले प्राथमिकता देने का एक तरीका है. साथ ही, यह किसी प्रोग्राम के लिए इंक्रीमेंटल पार्टिशनिंग की अनुमति देता है.
प्राथमिकताएं, sharding के कुछ या सभी डाइमेंशन से जुड़ी वैल्यू होती हैं. डुप्लीकेट किए गए ऐक्सिस की प्राथमिकताएं नहीं होतीं.
उदाहरण के लिए:
@mesh_xy = <["w"=6, "x"=2, "y"=4, "z"=2]>
// |-> y is implicitly p0
%arg4 : sharding<@mesh_xy, [{"x"}p1, {"y"}, {"z",?}p2], replicated={} }>
प्राथमिकताएं तय करने से, उपयोगकर्ताओं को डेटा प्रोपेगेशन पर ज़्यादा बेहतर कंट्रोल मिलता है. उदाहरण के लिए, सबसे पहले बैच पैरलललिज़्म, फिर megatron, और आखिर में ZeRO का इस्तेमाल करके डेटा को अलग-अलग हिस्सों में बांटना. इससे, यह पक्का किया जा सकता है कि किस डेटा को अलग-अलग हिस्सों में बांटा गया है. साथ ही, बेहतर तरीके से डीबग करने के लिए, ज़्यादा बेहतर शर्डिंग की रणनीतियां अपनाई जा सकती हैं. इससे यह देखा जा सकता है कि सिर्फ़ मेगाट्रॉन को अलग करने के बाद प्रोग्राम कैसा दिखता है.
हम हर डाइमेंशन के लिए प्राथमिकता (डिफ़ॉल्ट रूप से 0) जोड़ने की अनुमति देते हैं. इससे पता चलता है कि प्राथमिकता <i वाली सभी sharding, प्राथमिकता i वाली sharding से पहले पूरे प्रोग्राम में भेजी जाएंगी.
भले ही, किसी शर्डिंग में कम प्राथमिकता वाला कोई ओपन डाइमेंशन हो, जैसे कि {"z",?}p2,
प्रोपगेशन के दौरान, ज़्यादा प्राथमिकता वाले किसी दूसरे टेंसर को shaer करने की प्रोसेस से इसे बदला नहीं जाएगा. हालांकि, ज़्यादा प्राथमिकता वाले सभी डाइमेंशन को शेयर करने के बाद, इस तरह के ओपन डाइमेंशन को फिर से शेयर किया जा सकता है.
दूसरे शब्दों में, प्राथमिकताएं इस बात पर NOT होती हैं कि डाइमेंशन का कौनसा स्प्लिट, दूसरे स्प्लिट से ज़्यादा अहम है. यह क्रम है कि डाइमेंशन के अलग-अलग ग्रुप के स्प्लिट, पूरे प्रोग्राम में किस क्रम में लागू होने चाहिए. साथ ही, यह भी तय करता है कि इंटरमीडिएट और बिना एनोटेट किए गए टेंसर के बीच होने वाले संघर्षों को कैसे हल किया जाना चाहिए.
इनवैरिएंट
प्राथमिकताएं 0 (सबसे ज़्यादा प्राथमिकता) से शुरू होती हैं और बढ़ती जाती हैं.उपयोगकर्ताओं को प्राथमिकताएं आसानी से जोड़ने और हटाने की अनुमति देने के लिए, हम प्राथमिकताओं के बीच अंतर की अनुमति देते हैं. उदाहरण के लिए, p0 और p2 का इस्तेमाल किया जाता है, लेकिन p1 का नहीं.
खाली क्लोज़्ड डाइमेंशन का शार्डिंग (यानी,
{}) को प्राथमिकता नहीं दी जानी चाहिए, क्योंकि इससे कोई असर नहीं पड़ेगा.
डाइमेंशन को कितने हिस्सों में बांटा जा सकता है
साइज़ d वाले किसी डाइमेंशन को ऐसे ऐक्सिस के हिसाब से शेयर किया जा सकता है जिनके साइज़ का प्रॉडक्ट n है. ऐसा इसलिए, ताकि d को n से भाग न दिया जा सके. हालांकि, इसके लिए डाइमेंशन को पैड करना पड़ सकता है.
उदाहरण के लिए:
@mesh_xy = <["x"=8, "y"=2, "z"=3]>
sharding<@mesh_xy, [{"x"}, {"y"}, {"z"}]> : tensor<7x3x8xf32>
व्याकरण
हर लॉजिकल मेश को इस तरह से तय किया जाता है:
@mesh_name = <mesh_axis_1,...,mesh_axis_n>
mesh_axis ::= axis_name=axis_size
axis_name ::= str
axis_size ::= int
रैंक r के टेंसर के लिए, sharding के तौर पर दिखाए जाने वाले टेंसर का स्ट्रक्चर इस तरह का होगा:
sharding<@mesh_name, dim_shardings, replicated=replicated_axes}
mesh_name ::= str
dim_shardings ::= [dim_sharding_1,...,dim_sharding_r]
replicated_axes ::= {axis_1,...,axis_m}
dim_sharding ::=
{axis_1,...,axis_k} | // closed dimension
{axis_1,...,axis_k,?} // open dimension
axis ::=
axis_name | // a full axis
sub_axis // a sub axis
axis_name ::= str
sub_axis ::= axis_name:(pre_size)size
pre_size ::= int
size ::= int