
Фон
Целью представления сегментации является указание того, как тензор сегментируется относительно набора доступных устройств.
Представление сегментации может быть:
- Указывается пользователем вручную как ограничения сегментирования на входах, выходах или промежуточных данных.
- Преобразуется за одну операцию в процессе распространения шардинга.
Обзор
Базовая структура
Логическая сетка — это многомерное представление устройств, определяемое списком имен осей и размеров.
Предлагаемое представление шардинга привязано к определенной логической сетке по ее имени и может ссылаться только на имена осей из этой сетки. Шардинг тензора определяет, по каким осям (определенной логической сетки) каждое измерение тензора шардируется, упорядоченным от главного к второстепенному. Тензор реплицируется по всем остальным осям сетки.
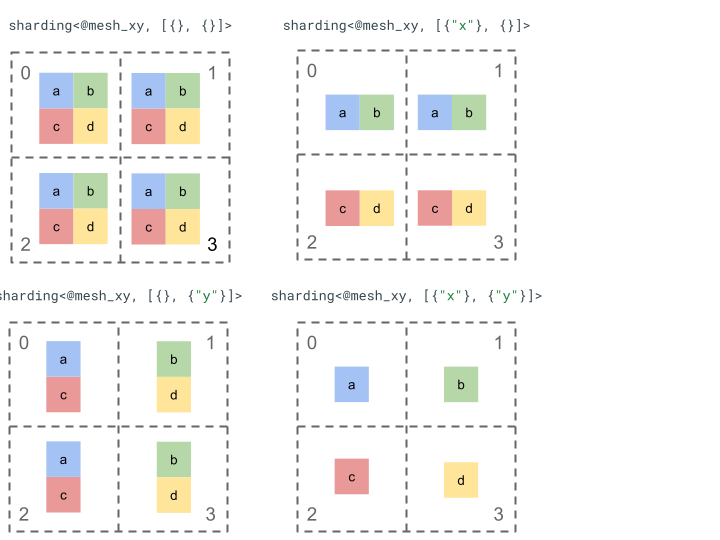
Давайте рассмотрим представление шардинга с помощью простого тензора ранга 2 и 4 устройств.
Сначала преобразуем 4 устройства [0, 1, 2, 3] в двумерный массив [[0, 1], [2, 3]] чтобы создать сетку с 2 осями:
@mesh_dm = <["d"=2, "m"=2]>
Где "d" представляет строки двумерной матрицы, а "m" столбцы.
Затем мы можем разбить на сегменты следующий тензор ранга 2 [[a, b], [c, d]] следующим образом:
Другие ключевые компоненты
- Открытые/закрытые измерения — измерения могут быть открытыми — их можно дополнительно сегментировать по доступным осям; или закрытыми — они фиксированы и не могут быть изменены.
- Явно реплицированные оси — все оси, которые не используются для сегментирования измерения, неявно реплицируются, но сегментирование может указывать оси, которые явно реплицируются и, следовательно, не могут быть использованы для сегментирования измерения в дальнейшем.
- Разделение осей и подоси — (полная) ось сетки может быть разделена на несколько подосей, которые могут использоваться по отдельности для сегментирования измерения или явно реплицироваться.
- Несколько логических сеток — разные сегменты могут быть привязаны к разным логическим сеткам, которые могут иметь разные оси или даже разный порядок идентификаторов логических устройств.
- Приоритеты — для поэтапного разделения программы приоритеты можно прикрепить к сегментациям измерений, которые определяют, в каком порядке ограничения сегментации по измерениям будут распространяться по всему модулю.
- Делимость сегментации измерения — измерение можно сегментировать по осям, произведение размеров которых не делит размер измерения.
Детальное проектирование
В этом разделе мы подробно рассмотрим базовую структуру и каждый ключевой компонент.
Базовая структура
Шардинги измерений говорят нам для каждого измерения тензора, по каким осям (или подосям ) он шардируется от главного к второстепенному. Все остальные оси, которые не шардируют измерение, неявно реплицируются (или явно реплицируются ).
Начнем с простого примера и расширим его, описав дополнительные функции.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// The 1st tensor dimension is sharded along axis "x" and the 2nd tensor
// dimension is sharded along axis "z" then further along axis "y".
// The local shape of this tensor (i.e. the shape on a single device),
// would be tensor<2x1xf32>.
sharding<@mesh_xyz, [{"x"}, {"z", "y"}]> : tensor<4x8xf32>
Инварианты
- Число сегментов измерения должно соответствовать рангу тензора.
- Все имена осей должны существовать в указанной сетке.
- Оси или подоси могут появляться в представлении сегментирования только один раз (каждая из них либо сегментирует измерение, либо явно реплицируется ).
Открытые/закрытые размеры
Каждое измерение тензора может быть открытым или закрытым.
Открыть
Открытое измерение открыто для распространения для дальнейшего его сегментирования по дополнительным осям, т. е. указанное сегментирование измерения не обязательно должно быть окончательным сегментированием этого измерения. Это похоже (но не совсем то же самое) на unspecified_dims GSPMD.
Если измерение открыто, мы добавляем знак ? после осей, по которым измерение уже сегментировано (см. пример ниже).
Обратите внимание, что ни один атрибут сегментирования тензора не эквивалентен полностью открытому сегментированию тензора.
Закрыто
Закрытое измерение — это измерение, которое недоступно для распространения для добавления дальнейшего шардинга, т. е. указанное шардинг измерения является окончательным шардингом этого измерения и не может быть изменено. Обычный случай использования этого — как GSPMD (обычно) не изменяет аргументы ввода/вывода модуля, или как с jax.jit , указанный пользователем in_shardings является статическим — он не может измениться.
Мы можем расширить приведенный выше пример, включив в него открытое и закрытое измерения.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// The 1st dimension is closed, therefore it can't be further sharded and {"x"}
// will remain its sharding. The 2nd dimension is open, and can therefore be
// further sharded during propagation, e.g. by "y".
sharding<@mesh_xyz, [{"x"}, {"z", ?}]> : tensor<4x8xf32>
Явно реплицированные оси
Явный набор осей, на которых реплицируется тензор. Хотя можно определить, что тензор, не разбитый на оси, неявно реплицируется на ней (как jax.sharding.PartitionSpec сегодня), наличие его явного указания гарантирует, что распространение не сможет использовать эти оси для дальнейшего осколка открытого измерения с этими осями. При неявной репликации тензор может быть еще больше разделен. Но при явной репликации ничто не может разделить тензор вдоль этой оси.
Порядок реплицированных осей не влияет на то, как хранятся данные тензора. Но, только для согласованности, оси будут храниться в том порядке, в котором они указаны в сетке верхнего уровня. Например, если сетка:
@mesh_cab = <["c"=2, "a"=2, "b"=2]>
И мы хотим, чтобы оси "a" и "c" были явно реплицированы, порядок должен быть следующим:
replicated={"c", "a"}
Мы можем расширить наш пример выше, чтобы получить явно реплицированную ось.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// Since "y" is explicitly replicated, it can't be used to shard the 2nd
// dimension that is open. However, "z" is implicitly replicated so it can be
// used to shard any dimension. "z" doesn't shard any dimension here, so the
// local shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x8xf32>.
sharding<@mesh_xyz, [{"x"}, {?}], replicated={"y"}> : tensor<4x8xf32>
Разделение осей и подосей
Логическая сетка из n осей создается путем преобразования одномерного массива устройств в n-мерный массив, где каждое измерение образует ось с именем, определяемым пользователем.
Тот же процесс можно выполнить в компиляторе, чтобы разбить ось размером k на m подосей, изменив сетку с [...,k,...] на [...,k1,...,km,...] .
Мотивация
Чтобы понять мотивацию разделения топоров, рассмотрим следующий пример:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 : (tensor<8xf32>) -> tensor<2x4xf32>
Мы хотим сегментировать результат изменения формы таким образом, чтобы избежать коммуникации (т. е. сохранить данные там, где они есть). Поскольку размер "x" больше, чем 1-е измерение результата, нам нужно разделить ось на две подоси "x.0" и "x.1" размером 2 каждая и сегментировать 1-е измерение на "x.0" и 2-е измерение на "x.1" .
Функция ввода/вывода шардингов
Возможно, что во время распространения вход или выход основной функции станет шардированным вдоль подоси. Это может быть проблемой для некоторых фреймворков, где мы не можем выразить такие шардинги, чтобы вернуть их пользователю (например, в JAX мы не можем выразить подоси с помощью jax.sharding.NamedSharding ).
У нас есть несколько вариантов решения таких случаев:
- Разрешить и вернуть шардинг в другом формате (например,
jax.sharding.PositionalShardingвместоjax.sharding.NamedShardingв JAX). - Запретить и полностью собрать подоси, которые разделяют вход/выход.
В настоящее время мы разрешаем подоси на входах/выходах в конвейере распространения. Дайте нам знать, если вам нужен способ отключить это.
Представление
Точно так же, как мы можем ссылаться на определенные полные оси сетки по их имени, мы можем ссылаться на определенные подоси по их размеру и произведению размеров всех подосей (с тем же именем оси) слева от них (которые являются для них основными).
Чтобы извлечь определенную подось размера k из полной оси "x" размера n , мы фактически преобразуем размер n (в сетке) в [m, k, n/(m*k)] и используем 2-е измерение в качестве подоси. Таким образом, подось может быть определена двумя числами, m и k , и мы используем следующую краткую нотацию для обозначения подосей: "x":(m)k .
m>=1— это предварительный размер этой подоси (mдолжно быть делителемn). Предварительный размер — это произведение всех размеров подосей слева от (которые являются главными по отношению к) этой подоси (если равно 1, это означает, что их нет, если больше 1, это соответствует одной или нескольким подосям).k>1— фактический размер этой подоси (kдолжно быть делителемn).n/(m*k)— размер поста . Это произведение всех размеров подосей справа от (которые являются меньшими по отношению к) этой подоси (если равно 1, это означает, что их нет, если больше 1, это соответствует одной или нескольким подосям).
Однако количество других подосей не имеет значения при использовании конкретной подоси "x":(m)k , и любая другая подось не нуждается в ссылке при сегментировании тензора, если она не сегментирует измерение или явно реплицируется.
Возвращаясь к примеру в разделе «Мотивация» , мы можем сегментировать результат следующим образом:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 {sdy.sharding_per_value=<[<@mesh_x, [{"x":(1)2}, {"x":(2)2}]>]>}
: (tensor<8xf32>) -> tensor<2x4xf32>
Вот еще один пример разделенной оси, в которой используются только некоторые из ее подосей.
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Axis "y" is effectively split into 3 sub-axes denoted as
// "y":(1)2, "y":(2)2, "y":(4)2
// in order, but only "y":(2)2 is used, to shard the 2nd dimension. The local
// shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x4xf32>.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}]> : tensor<4x8xf32>
Аналогично, следующие два шардинга семантически эквивалентны. Мы можем думать о mesh_xy как о разделении mesh_full .
@mesh_full = <"devices"=8>
@mesh_xy = <"x"=4, "y"=2>
sharding<@mesh_xy, [{"x"},{ "y"}]> : tensor<4x4xf32>
sharding<@mesh_full, [{"devices":(1)4}, {"devices":(4)2}]> : tensor<4x4xf32>
Явно реплицированные подоси
В дополнение к использованию подосей для сегментации измерения, они также могут быть помечены как явно реплицированные. Мы допускаем это в представлении, поскольку подоси ведут себя так же, как полные оси, т. е. когда вы сегментируете измерение вдоль подоси оси "x" , другие подоси "x" неявно реплицируются и, следовательно, могут быть явно реплицированы, чтобы указать, что подось должна оставаться реплицированной и не может использоваться для сегментации измерения.
Например:
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Sub-axis "y":(1)2 is explicitly replicated and "y":(4)2 is implicitly replicated.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}], replicated={"y":(1)2}> : tensor<4x8xf32>
Повторяющиеся подоси одной и той же полной оси должны быть упорядочены в порядке возрастания их предварительного размера, например:
replicated={"y":(4)2, "x", "y":(1)2} ~> replicated={"x", "y":(1)2, "y":(4)2}
Инварианты
Подоси, на которые ссылаются в тензорном сегментировании, не должны перекрываться, например
"x":(1)4и"x":(2)4перекрываются.Подоси, на которые ссылаются в сегментировании тензора, должны быть как можно больше, т. е. если сегментирование измерения имеет две смежные подоси A и B по порядку или подоси A и B явно реплицируются, они не должны быть последовательными, например
"x":(1)2и"x":(2)4поскольку их можно заменить одним"x":(1)8.
Несколько логических сеток
Одна логическая сетка — это многомерное представление устройств. Нам может понадобиться несколько представлений устройств для представления наших шардингов, особенно для произвольных назначений устройств.
Например, jax.sharding.PositionalSharding не имеет одной общей логической сетки . В настоящее время GSPMD поддерживает это с помощью HloSharding, где представление может быть упорядоченным списком устройств и размеров измерений, но это не может быть представлено с помощью разделения осей, описанного выше.
Мы преодолеваем это ограничение и обрабатываем существующие угловые случаи, определяя несколько логических сеток на верхнем уровне программы. Каждая сетка может иметь разное количество осей с разными именами, а также свое собственное произвольное назначение для одного и того же набора устройств, т. е. каждая сетка ссылается на один и тот же набор устройств (по их уникальному логическому идентификатору), но с произвольным порядком, аналогично представлению GSPMD.
Каждое представление сегментации связано с определенной логической сеткой, поэтому оно будет ссылаться только на оси этой сетки.
Тензор, назначенный одной логической сетке, может использоваться оператором, назначенным другой сетке, путем наивного перешардирования тензора для соответствия целевой сетке. В GSPMD это обычно делается для разрешения конфликтующих сеток.
Пользователи могут указать несколько сеток с разными именованными осями (например, через jax.sharding.NamedSharding ), которые имеют одинаковый порядок устройств. Рассмотрим этот пример, <@mesh_0, "b"> идентично <@mesh_1, "z"> :
@mesh_0 = {<["a"=4, "b"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
@mesh_1 = {<["x"=2, "y"=2, "z"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
Приоритеты
Приоритет — это способ приоритизации определенных решений по разбиению и распространению по сравнению с другими, позволяющий выполнять инкрементное разбиение программы.
Приоритеты — это значения, присвоенные некоторым или всем измерениям представления сегментирования (реплицированные оси не имеют приоритетов).
Например:
@mesh_wxyz = <["w"=6, "x"=2, "y"=4, "z"=2]>
// |-> y is implicitly p0
%arg4 : sharding<@mesh_wxyz, [{"x"}p1, {"y"}, {"z",?}p2], replicated={} }>
Приоритеты дают пользователям более детальный контроль над распространением, например, сначала пакетный параллелизм, затем megatron и, наконец, шардинг ZeRO . Это обеспечивает надежные гарантии того, что разделено, и позволяет улучшить отладку за счет более детальных стратегий шардинга (можно увидеть, как программа выглядит после megatron в изоляции).
Мы разрешаем назначать приоритет каждому сегментированию измерения (по умолчанию 0), что означает, что все сегментации с приоритетом <i будут распространены на всю программу раньше сегментаций с приоритетом i .
Даже если шардинг имеет открытое измерение с более низким приоритетом, например, {"z",?}p2 , он не будет переопределен другим шардингом тензора с более высоким приоритетом во время распространения. Однако такое открытое измерение может быть далее шардировано после того, как все шардинги с более высоким приоритетом были распространены.
Другими словами, приоритеты НЕ касаются того, какое сегментирование измерений важнее другого, а касаются порядка, в котором отдельные группы сегментаций измерений должны распространяться на всю программу, и того, как должны разрешаться конфликты в промежуточных, неаннотированных тензорах.
Инварианты
Приоритеты начинаются с 0 (самый высокий приоритет) и увеличиваются (чтобы пользователи могли легко добавлять и удалять приоритеты, мы допускаем пробелы между приоритетами, например, p0 и p2 используются, а p1 — нет).
Пустое замкнутое сегментирование измерений (т. е.
{}) не должно иметь приоритета, поскольку это не даст никакого эффекта.
Делимость сегментирования измерений
Измерение размера d можно разбить по осям, произведение размеров которых равно n , так что d не будет делиться на n (что на практике потребовало бы дополнения измерения).
Например:
@mesh_xyz = <["x"=8, "y"=2, "z"=3]>
sharding<@mesh_xyz, [{"x"}, {"y"}, {"z"}]> : tensor<7x3x8xf32>
Грамматика
Каждая логическая сетка определяется следующим образом:
@mesh_name = <mesh_axis_1,...,mesh_axis_n>
mesh_axis ::= axis_name=axis_size
axis_name ::= str
axis_size ::= int
Представление шардинга будет иметь следующую структуру для тензора ранга r:
sharding<@mesh_name, dim_shardings, replicated=replicated_axes}
mesh_name ::= str
dim_shardings ::= [dim_sharding_1,...,dim_sharding_r]
replicated_axes ::= {axis_1,...,axis_m}
dim_sharding ::=
{axis_1,...,axis_k} | // closed dimension
{axis_1,...,axis_k,?} // open dimension
axis ::=
axis_name | // a full axis
sub_axis // a sub axis
axis_name ::= str
sub_axis ::= axis_name:(pre_size)size
pre_size ::= int
size ::= int