
Latar belakang
Tujuan representasi sharding adalah untuk menentukan cara tensor di-sharding sehubungan dengan serangkaian perangkat yang tersedia.
Representasi sharding dapat berupa:
- Ditentukan secara manual oleh pengguna sebagai batasan sharding pada input, output, atau perantara.
- Diubah per operasi dalam proses penyebaran sharding.
Ringkasan
Struktur dasar
Mesh logis adalah tampilan multidimensi perangkat, yang ditentukan oleh daftar nama dan ukuran sumbu.
Representasi sharding yang diusulkan terikat dengan mesh logis tertentu berdasarkan namanya, dan hanya dapat mereferensikan nama sumbu dari mesh tersebut. Sharding tensor menentukan sumbu mana (dari mesh logis tertentu) setiap dimensi tensor di-sharding, yang diurutkan dari utama ke minor. Tensor direplikasi di sepanjang semua sumbu mesh lainnya.
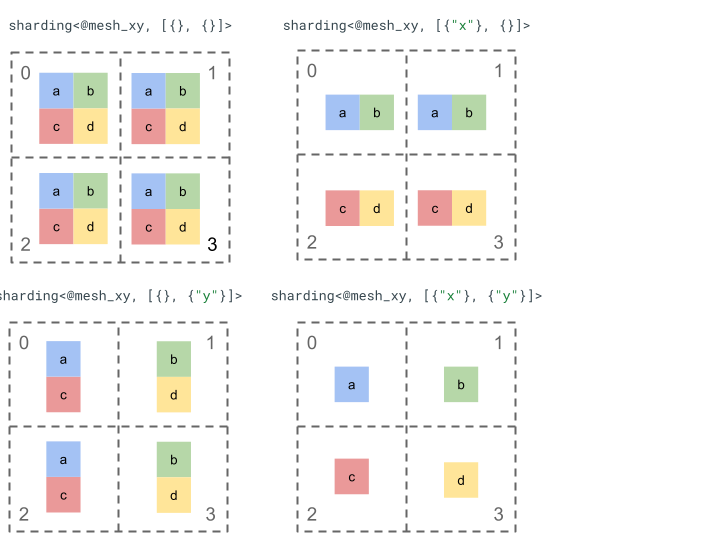
Mari kita jelajahi representasi sharding dengan tensor peringkat 2 sederhana dan 4 perangkat.
Pertama, kita mengubah bentuk 4 perangkat [0, 1, 2, 3] menjadi array 2 dimensi [[0, 1], [2,
3]] untuk membuat mesh dengan 2 sumbu:
@mesh_xy = <["x"=2, "y"=2]>
Kemudian, kita dapat membuat shard tensor [[a, b], [c, d]] peringkat 2 berikut sebagai berikut:
Komponen utama lainnya
- Dimensi Terbuka/Tertutup - dimensi dapat terbuka - dapat di-shard lebih lanjut pada sumbu yang tersedia; atau tertutup - bersifat tetap dan tidak dapat diubah.
- Sumbu yang direplikasi secara eksplisit - semua sumbu yang tidak digunakan untuk membuat shard dimensi direplikasi secara implisit, tetapi shading dapat menentukan sumbu yang direplikasi secara eksplisit sehingga tidak dapat digunakan untuk membuat shard dimensi di lain waktu.
- Pembagian sumbu dan sub-sumbu - sumbu mesh (lengkap) dapat dibagi menjadi beberapa sub-sumbu yang dapat digunakan secara terpisah untuk membuat shard dimensi atau direplikasi secara eksplisit.
- Beberapa mesh logis - sharding yang berbeda dapat terikat ke mesh logis yang berbeda, yang dapat memiliki sumbu yang berbeda atau bahkan urutan ID perangkat logis yang berbeda.
- Prioritas - untuk mempartisi program secara bertahap, prioritas dapat dilampirkan ke sharding dimensi, yang menentukan dalam urutan mana batasan sharding per dimensi akan disebarkan di seluruh modul.
- Pembagian sharding dimensi - dimensi dapat di-sharding pada sumbu yang produk ukurannya tidak membagi ukuran dimensi.
Desain Terperinci
Kami memperluas struktur dasar dan setiap komponen utama di bagian ini.
Struktur dasar
Sharding dimensi memberi tahu kita untuk setiap dimensi tensor, yang sepanjang sumbu (atau sub-sumbu) di-sharding dari utama ke minor. Semua sumbu lain yang tidak melakukan shard dimensi direplikasi secara implisit (atau direplikasi secara eksplisit).
Kita akan memulai dengan contoh sederhana dan memperluasnya saat kita menjelaskan fitur tambahan.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st tensor dimension is sharded along axis "x" and the 2nd tensor dimension is
// sharded along axis "z" then further along axis "y". The local shape of this tensor (i.e. the shape on a single device), would be tensor<2x1xf32>.
sharding<@mesh_xy, [{"x"}, {"z", "y"}]> : tensor<4x8xf32>
Invarian
- Jumlah sharding dimensi harus cocok dengan peringkat tensor.
- Semua nama sumbu harus ada di mesh yang direferensikan.
- Sumbu atau sub-sumbu hanya dapat muncul sekali dalam representasi sharding (masing-masing membagi dimensi atau direplikasi secara eksplisit).
Dimensi terbuka/tertutup
Setiap dimensi tensor dapat terbuka atau tertutup.
Buka
Dimensi terbuka terbuka untuk penyebaran guna melakukan shard lebih lanjut di sepanjang sumbu tambahan, yaitu sharding dimensi yang ditentukan tidak harus merupakan sharding akhir dimensi tersebut. Ini mirip (tetapi tidak sama persis dengan)
unspecified_dims GSMPD.
Jika dimensi terbuka, kita akan menambahkan ? mengikuti sumbu tempat dimensi tersebut sudah di-shard (lihat contoh di bawah).
Tertutup
Dimensi tertutup adalah dimensi yang tidak tersedia untuk propagasi guna menambahkan sharding
lebih lanjut, yaitu sharding dimensi yang ditentukan adalah sharding akhir dari dimensi
tersebut dan tidak dapat diubah. Kasus penggunaan umum untuk hal ini adalah cara GSPMD
(biasanya) tidak mengubah argumen input/output modul, atau cara dengan
jax.jit, in_shardings yang ditentukan pengguna bersifat statis - tidak dapat berubah.
Kita dapat memperluas contoh dari atas untuk memiliki dimensi terbuka dan dimensi tertutup.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st dimension is closed, therefore it can't be further sharded and {"x"}
// will remain its sharding. The 2nd dimension is open, and can therefore be
// further sharded during propagation, e.g. by "y".
sharding<@mesh_xy, [{"x"}, {"z", ?}]> : tensor<4x8xf32>
Sumbu yang direplikasi secara eksplisit
Kumpulan sumbu eksplisit tempat tensor direplikasi. Meskipun dapat
ditentukan bahwa tensor yang tidak di-shard pada sumbu direplikasi secara implisit di sumbu tersebut
(seperti
jax.sharding.PartitionSpec
saat ini), membuatnya eksplisit akan memastikan bahwa propagasi tidak dapat menggunakan sumbu ini untuk
mem-shard lebih lanjut dimensi terbuka dengan sumbu tersebut. Dengan replikasi implisit, tensor dapat dipartisi lebih lanjut. Namun, dengan replikasi eksplisit, tidak ada yang dapat
mempartisi tensor di sepanjang sumbu tersebut.
Pengurutan sumbu yang direplikasi tidak memengaruhi cara penyimpanan data tensor. Namun, hanya untuk konsistensi, sumbu akan disimpan dalam urutan yang ditentukan dalam mesh tingkat teratas. Misalnya, jika mesh adalah:
@mesh_xy = <["c"=2, "a"=2, "b"=2]>
Dan kita ingin sumbu "a" dan "c" direplikasi secara eksplisit, urutannya harus
berbentuk:
replicated={"c", "a"}
Kita dapat memperluas contoh dari atas untuk memiliki sumbu yang direplikasi secara eksplisit.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// Since "y" is explicitly replicated, it can't be used to shard the 2nd
// dimension that is open. However, "z" is implicitly replicated so it can be
// used to shard that dimension. The local shape of this tensor (i.e. the
// shape on a single device), would be tensor<2x8xf32>.
sharding<@mesh_xyz, [{"x"}, {?}], replicated={"y"}> : tensor<4x8xf32>
Pemisahan sumbu dan sub-sumbu
Mesh logis sumbu n dibuat dengan membentuk ulang array perangkat 1 dimensi
menjadi array n dimensi, dengan setiap dimensi membentuk sumbu dengan
nama yang ditentukan pengguna.
Proses yang sama dapat dilakukan di compiler untuk membagi sumbu berukuran k
lebih lanjut menjadi sub-sumbu m, dengan membentuk ulang mesh dari [...,k,...] menjadi
[...,k1,...,km,...].
Motivasi
Untuk memahami motivasi di balik pemisahan sumbu, kita akan melihat contoh berikut:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 : (tensor<8xf32>) -> tensor<2x4xf32>
Kita ingin membuat shard hasil pembentukan ulang dengan cara yang akan menghindari
komunikasi (yaitu mempertahankan data di tempatnya). Karena ukuran "x"
lebih besar dari dimensi ke-1 hasil, kita perlu membagi sumbu menjadi dua
sub-sumbu "x.0" dan "x.1" dengan ukuran masing-masing 2, dan membuat shard dimensi ke-1 di
"x.0" dan dimensi ke-2 di "x.1".
Sharding Input/output fungsi
Selama penyebaran, input atau output fungsi utama
mungkin akan di-shard di sepanjang sub-sumbu. Hal ini dapat menjadi masalah bagi beberapa framework,
karena kita tidak dapat mengekspresikan sharding tersebut untuk diberikan kembali kepada pengguna (misalnya, di JAX kita
tidak dapat mengekspresikan sub-sumbu dengan
jax.sharding.NamedSharding).
Kami memiliki beberapa opsi untuk menangani kasus tersebut:
- Mengizinkan, dan menampilkan sharding dalam format yang berbeda (misalnya,
jax.sharding.PositionalSharding, bukanjax.sharding.NamedShardingdi JAX). - Tidak mengizinkan, dan sub-sumbu all-gather yang mengelompokkan input/output.
Saat ini kami mengizinkan sub-sumbu pada input/output di pipeline propagasi. Beri tahu kami jika Anda ingin cara untuk menonaktifkannya.
Representasi
Dengan cara yang sama seperti kita dapat mereferensikan sumbu penuh tertentu dari mesh berdasarkan namanya, kita dapat mereferensikan sub-sumbu tertentu berdasarkan ukurannya dan produk dari semua ukuran sub-sumbu (dari nama sumbu yang sama) di sebelah kirinya (yang utama baginya).
Untuk mengekstrak sub-sumbu tertentu berukuran k dari sumbu penuh "x" berukuran n,
kita secara efektif membentuk ulang ukuran n (dalam mesh) menjadi [m, k, n/(m*k)] dan menggunakan
dimensi ke-2 sebagai sub-sumbu. Dengan demikian, sub-sumbu dapat ditentukan oleh dua
angka, m dan k, dan kita menggunakan notasi ringkas berikut untuk menunjukkan
sub-sumbu: "x":(m)k.
m>=1adalah pra-ukuran sub-sumbu ini (mharus merupakan pembagin). Pra-ukuran adalah hasil dari semua ukuran sub-sumbu di sebelah kiri (yang utama untuk) sub-sumbu ini (jika sama dengan 1, berarti tidak ada, Jika lebih besar dari 1, berarti sesuai dengan satu atau beberapa sub-sumbu).k>1adalah ukuran sebenarnya dari sub-sumbu ini (kharus berupa pembagin).n/(m*k)adalah post-size. Ini adalah produk dari semua ukuran sub-sumbu di sebelah kanan (yang lebih kecil dari) sub-sumbu ini (jika sama dengan 1, berarti tidak ada, Jika lebih besar dari 1, ini sesuai dengan satu atau beberapa sub-sumbu).
Namun, jumlah sub-sumbu lain tidak membuat perbedaan saat menggunakan
sub-sumbu "x":(m)k tertentu, dan sub-sumbu lainnya tidak perlu
direferensikan dalam sharding tensor jika tidak melakukan sharding dimensi atau
direplikasi secara eksplisit.
Kembali ke contoh di bagian Motivasi, kita dapat mengelompokkan hasil sebagai berikut:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 {sdy.sharding_per_value=<[<@mesh_x, [{"x":(1)2}, {"x":(2)2}]>]>}
: (tensor<8xf32>) -> tensor<2x4xf32>
Berikut adalah contoh lain sumbu terpisah yang hanya menggunakan beberapa sub-sumbunya.
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Axis "y" is effectively split into 3 sub-axes denoted as
// "y":(1)2, "y":(2)2, "y":(4)2
// in order, but only "y":(2)2 is used, to shard the 2nd dimension. The local
// shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x4xf32>.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}]> : tensor<4x8xf32>
Demikian pula, dua sharding berikut setara secara semantik. Kita dapat menganggap
mesh_xy sebagai pemisahan mesh_full.
@mesh_full = <"devices"=8>
@mesh_xy = <"x"=4, "y"=2>
sharding<@mesh_xy, [{"x"},{ "y"}]> : tensor<4x4xf32>
sharding<@mesh_full, [{"devices":(1)4}, {"devices":(4)2}]> : tensor<4x4xf32>
Sub-sumbu yang direplikasi secara eksplisit
Selain sub-sumbu yang digunakan untuk membuat shard dimensi, sub-sumbu juga dapat ditandai
sebagai direplikasi secara eksplisit. Kami mengizinkan hal ini dalam representasi karena sub-sumbu
berperilaku seperti sumbu penuh, yaitu saat Anda membuat shard dimensi di sepanjang sub-sumbu
sumbu "x", sub-sumbu "x" lainnya direplikasi secara implisit, sehingga
dapat direplikasi secara eksplisit untuk menunjukkan bahwa sub-sumbu harus tetap direplikasi
dan tidak dapat digunakan untuk membuat shard dimensi.
Contoh:
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Sub-axis "y":(1)2 is explicitly replicated and "y":(4)2 is implicitly replicated.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}], replicated={"y":(1)2}> : tensor<4x8xf32>
Sub-sumbu yang direplikasi dari sumbu penuh yang sama harus diurutkan dalam urutan menaik berdasarkan ukuran sebelumnya, misalnya:
replicated={"y":(4)2, "x", "y":(1)2} ~> replicated={"x", "y":(1)2, "y":(4)2}
Invarian
Sub-sumbu yang dirujuk dalam sharding tensor tidak boleh tumpang-tindih, misalnya
"x":(1)4dan"x":(2)4tumpang-tindih.Sub-sumbu yang dirujuk dalam sharding tensor harus sebesar mungkin, yaitu jika sharding dimensi memiliki dua sub-sumbu A dan B yang berdekatan secara berurutan, atau sub-sumbu A dan B direplikasi secara eksplisit, sub-sumbu tersebut tidak boleh berurutan, misalnya
"x":(1)2dan"x":(2)4karena dapat diganti dengan satu"x":(1)8.
Beberapa mesh logis
Satu mesh logis adalah tampilan multidimensi perangkat. Kita mungkin memerlukan beberapa tampilan perangkat untuk mewakili sharding, terutama untuk penetapan perangkat arbitrer.
Misalnya,
jax.sharding.PositionalSharding tidak memiliki satu mesh logis umum.
GSPMD saat ini mendukungnya dengan HloSharding, dengan representasi yang dapat berupa
daftar perangkat dan ukuran dimensi yang diurutkan, tetapi hal ini tidak dapat direpresentasikan
dengan pemisahan sumbu di atas.
Kita mengatasi batasan ini dan menangani kasus ekstrem yang ada dengan menentukan beberapa mesh logis di tingkat atas program. Setiap mesh dapat memiliki jumlah sumbu yang berbeda dengan nama yang berbeda, serta penetapan arbitrernya sendiri untuk kumpulan perangkat yang sama, yaitu setiap mesh merujuk ke kumpulan perangkat yang sama (dengan ID logis uniknya) tetapi dengan urutan arbitrer, mirip dengan representasi GSMPD.
Setiap representasi sharding ditautkan ke mesh logis tertentu, sehingga hanya akan mereferensikan sumbu dari mesh tersebut.
Tensor yang ditetapkan ke satu mesh logis dapat digunakan oleh op yang ditetapkan ke mesh lain, dengan me-resharding tensor secara naif agar cocok dengan mesh tujuan. Di GSPMD, hal ini biasanya dilakukan untuk menyelesaikan mesh yang bertentangan.
Pengguna dapat menentukan beberapa mesh dengan sumbu bernama yang berbeda (misalnya melalui
jax.sharding.NamedSharding), yang memiliki urutan perangkat yang sama. Perhatikan
contoh ini, <@mesh_0, "b"> identik dengan <@mesh_1, "z">:
@mesh_0 = {<["a"=4, "b"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
@mesh_1 = {<["x"=2, "y"=2, "z"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
Prioritas
Prioritas adalah cara untuk memprioritaskan keputusan partisi dan penyebaran tertentu dibandingkan yang lain, dan memungkinkan partisi inkremental program.
Prioritas adalah nilai yang dilampirkan ke beberapa atau semua dimensi representasi sharding (sumbu yang direplikasi tidak memiliki prioritas).
Contoh:
@mesh_xy = <["w"=6, "x"=2, "y"=4, "z"=2]>
// |-> y is implicitly p0
%arg4 : sharding<@mesh_xy, [{"x"}p1, {"y"}, {"z",?}p2], replicated={} }>
Prioritas memberi pengguna kontrol yang lebih terperinci atas penyebaran, misalnya, paralelisme batch terlebih dahulu, lalu megatron, dan terakhir sharding ZeRO. Hal ini memungkinkan jaminan yang kuat tentang apa yang dipartisi dan memungkinkan kemampuan debug yang lebih baik dengan memiliki strategi sharding yang lebih terperinci (dapat melihat tampilan program setelah hanya megatron secara terpisah).
Kami mengizinkan penyertaan prioritas ke setiap sharding dimensi (0 secara default), yang
menunjukkan bahwa semua sharding dengan prioritas <i akan disebarkan ke seluruh
program sebelum sharding dengan prioritas i.
Meskipun sharding memiliki dimensi terbuka dengan prioritas lebih rendah, misalnya, {"z",?}p2,
tidak akan diganti oleh sharding tensor lain dengan prioritas yang lebih tinggi selama
penyebaran. Namun, dimensi terbuka tersebut dapat di-shard lebih lanjut setelah semua
sharding prioritas yang lebih tinggi telah di-propagate.
Dengan kata lain, prioritas NOT tentang sharding dimensi mana yang lebih penting daripada yang lain - ini adalah urutan penyebaran grup sharding dimensi yang berbeda ke seluruh program, dan cara konflik pada tensor menengah yang tidak dianotasi harus diselesaikan.
Invarian
Prioritas dimulai dari 0 (prioritas tertinggi) dan meningkat (agar pengguna dapat menambahkan dan menghapus prioritas dengan mudah, kami mengizinkan celah di antara prioritas, misalnya, p0 dan p2 digunakan, tetapi p1 tidak).
Sharding dimensi tertutup kosong (yaitu,
{}), tidak boleh memiliki prioritas, karena tidak akan berpengaruh.
Pembagian sharding dimensi
Dimensi berukuran d dapat di-shard di sepanjang sumbu yang produk
ukurannya adalah n, sehingga d tidak dapat dibagi dengan n (yang dalam praktiknya akan
memerlukan dimensi untuk ditambahkan padding).
Contoh:
@mesh_xy = <["x"=8, "y"=2, "z"=3]>
sharding<@mesh_xy, [{"x"}, {"y"}, {"z"}]> : tensor<7x3x8xf32>
Tata Bahasa
Setiap mesh logis ditentukan sebagai berikut:
@mesh_name = <mesh_axis_1,...,mesh_axis_n>
mesh_axis ::= axis_name=axis_size
axis_name ::= str
axis_size ::= int
Representasi sharding akan memiliki struktur berikut untuk tensor dengan peringkat r:
sharding<@mesh_name, dim_shardings, replicated=replicated_axes}
mesh_name ::= str
dim_shardings ::= [dim_sharding_1,...,dim_sharding_r]
replicated_axes ::= {axis_1,...,axis_m}
dim_sharding ::=
{axis_1,...,axis_k} | // closed dimension
{axis_1,...,axis_k,?} // open dimension
axis ::=
axis_name | // a full axis
sub_axis // a sub axis
axis_name ::= str
sub_axis ::= axis_name:(pre_size)size
pre_size ::= int
size ::= int